# 1.primitives(基础工具)
本章讲解基础的用于分配内存和销毁内存的”工具“。
# 1.1 内存分配的每一个层面
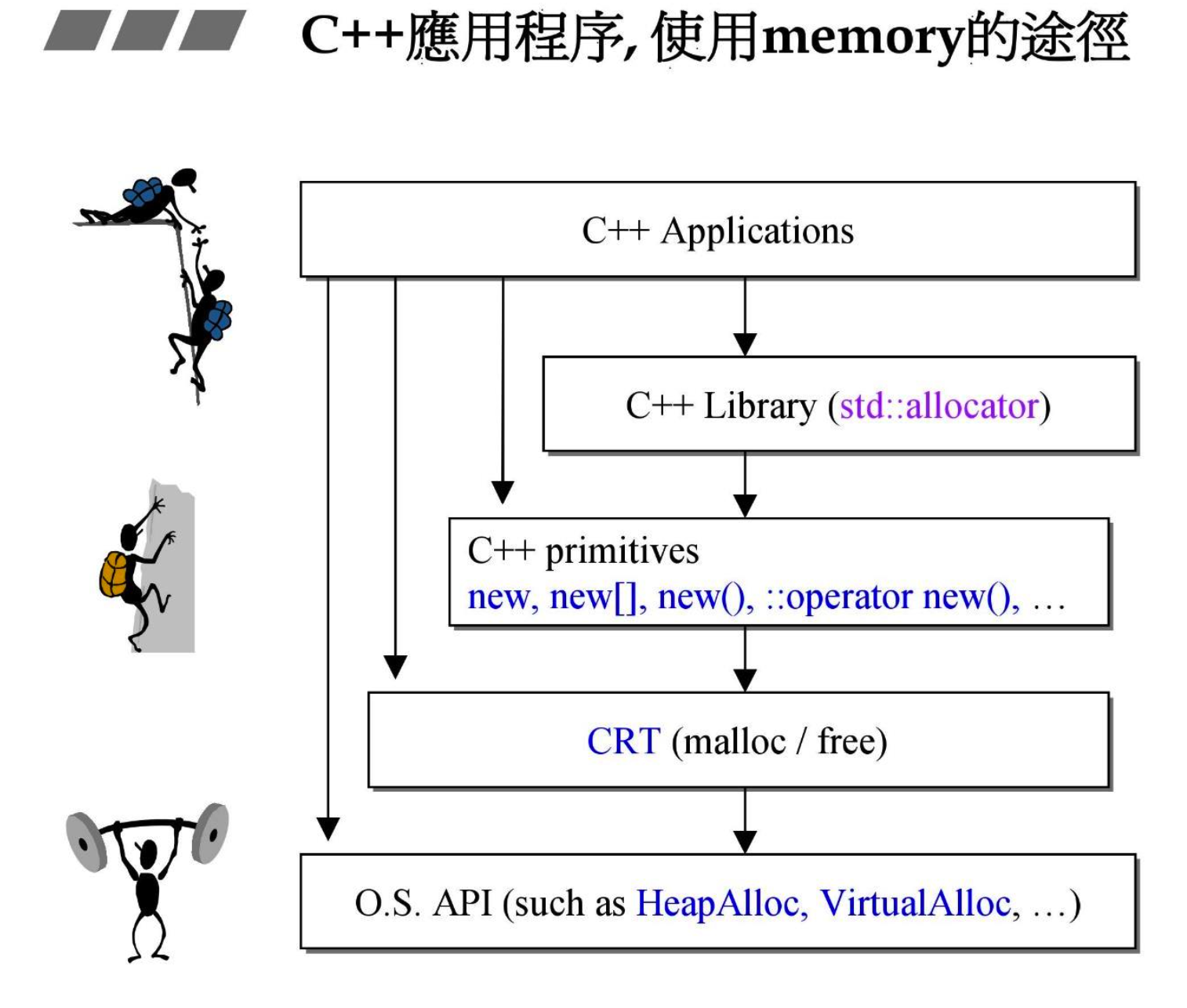
- C++ 应用程序可以通过多种方式调用内存分配的”工具“(即接口)
- 一般不会到操作系统 API,一个是会影响是可移植性,一个是太底层了
- 可以看出各种方式都会到 CRT(malloc/free) 上。CRT 指的是 C Runtime Library

- 四个我们手上可以用的基础工具
# 1.2 四个层面的基本用法

void* p3 = ::operator new(512);底层就是调用的malloc,::operator delete(p3);底层就是调用的free- VC、Borland C、GCC 的 allocator 写法有微小区别
- 一般人很少会用分配器分配内存,因为释放的时候要记住当初分配了多少内存,多是容器来用

- 新版 GCC 的 alloc 改了名字和用法
# 1.3 new/delete expression

- 用法:new 后面加 class 的名字
- new 的步骤
- 分配内存
- 转型(可以和上一步合到一起,这里拆开是为了看的更清楚)
- 调用构造函数
::operator new()是全局的函数,而该函数可以重载,如果它被重载了,那么调用的就是重载的函数。而此处的 Complex 类并没有重载operator new(),所以调用的就是全局的::operator new()- 在函数
opeartor new()中可以看到,调用了malloc() - 只有编译器才可以像 ③ 一样直接调用构造函数(注意,根据测试,有的编译器允许用户这么做,有的不行);如果程序想直接调用构造函数,可以使用 palcement new 的方式:
new(p) Complex(1,2);
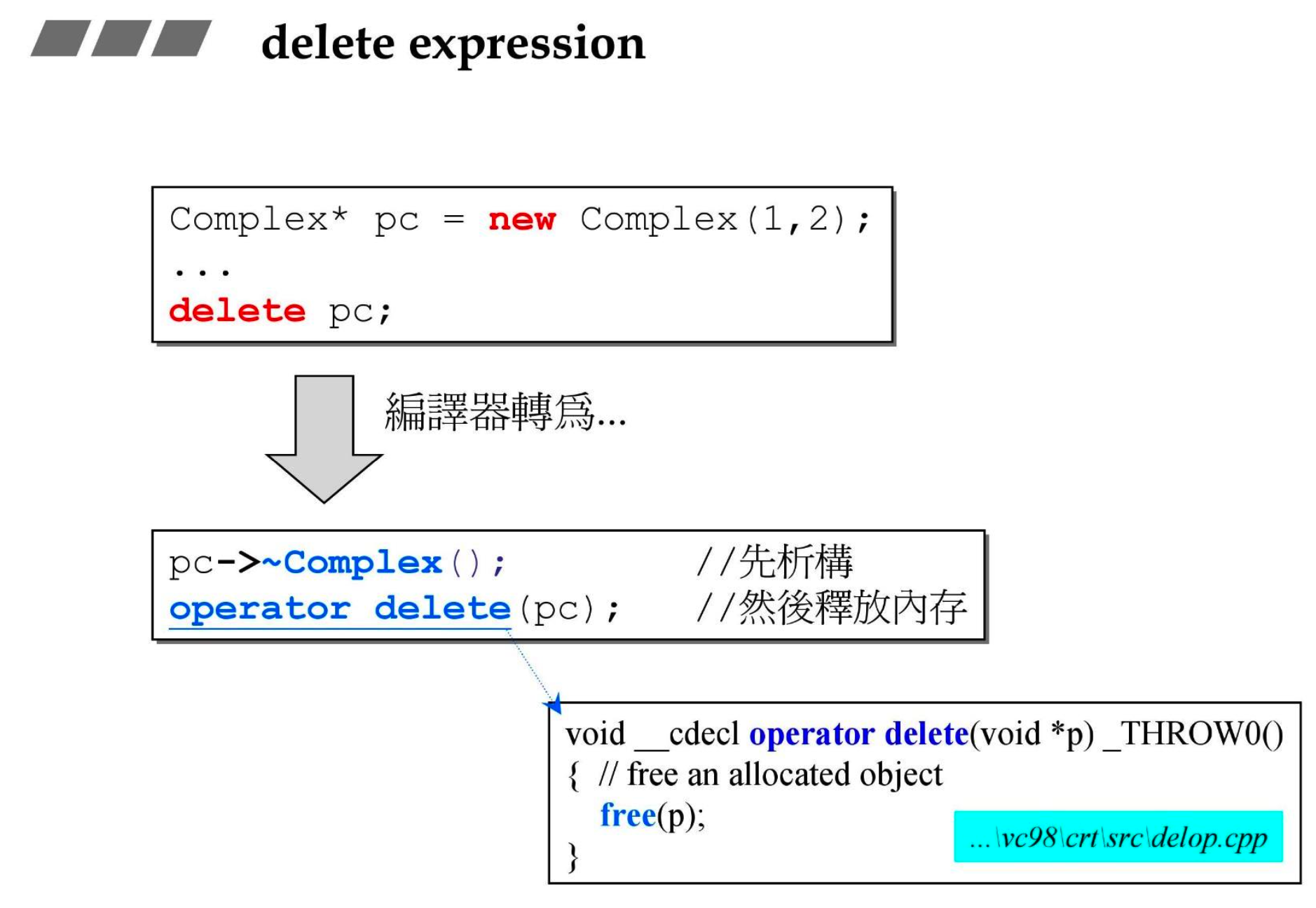
- 先调用析构函数再释放内存
- 可以用指针直接调用析构函数,没有问题
operator delete()函数底层就是调用的free()

- 测试是否如上面所说,不可以直接调用构造函数,但可以调用析构函数
- 通过指针调用构造函数:
pstr->string::string("jjhou");编译会失败 pstr->~string();其实是可以通过的,但因为上面没能调用构造函数,这行也执行不了- 为了更好的测试,自己写了一个类,说明确实不能直接调用构造函数
pA->A::A(3);在 VC6 中执行会成功,而在 GCC 中则会执行失败;A::A(5);在 VC6 中也执行成功,在 GCC 中执行失败
# 1.4 array new/delete
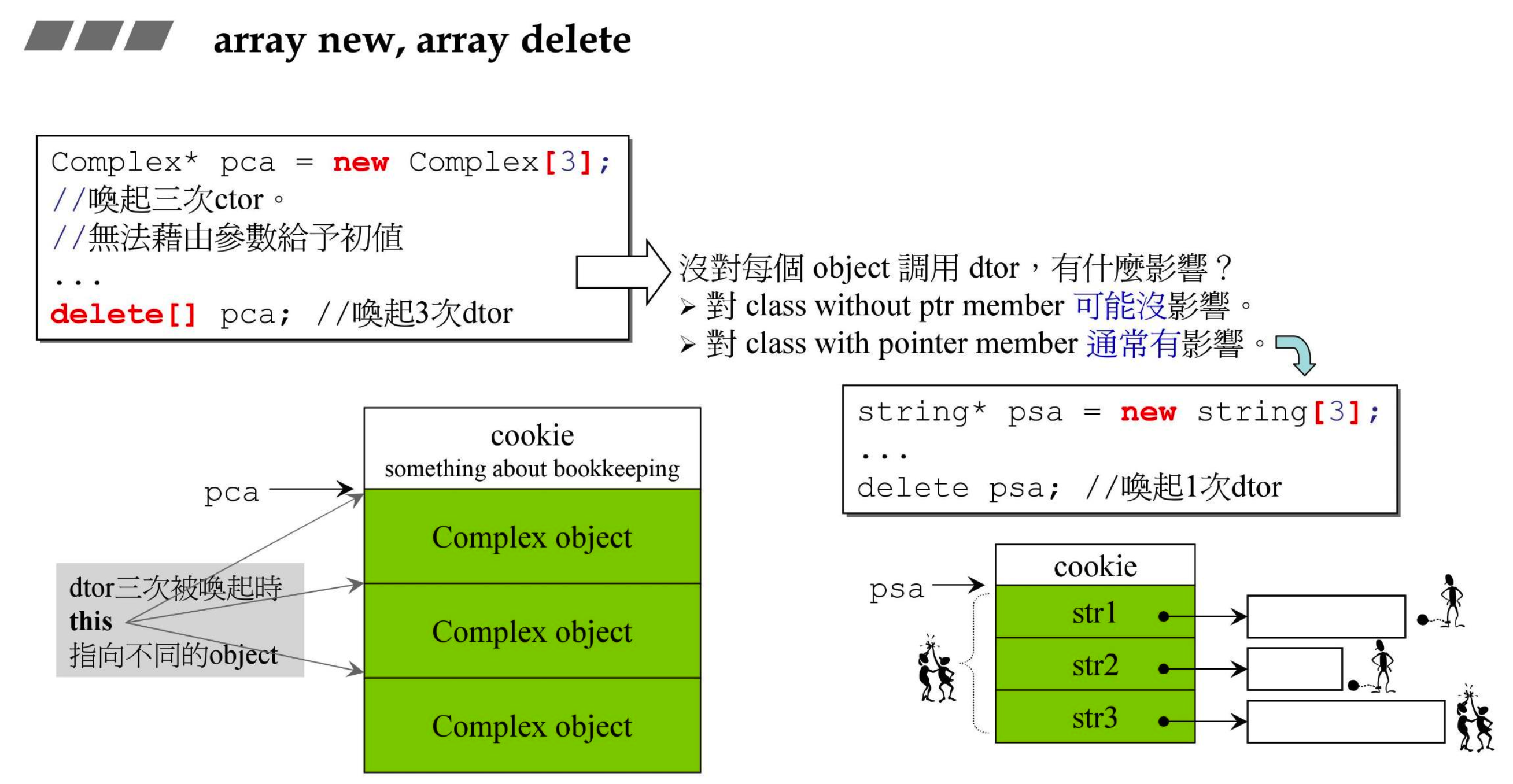
- 初学者很容易 new 的时候创建出 array,delete 的时候却忘记加
[],不写的话编译器会认为 delete 的是对象,只调用一次析构函数 - cookie 会记录 array 的长度,用 malloc 就会有 cookie
- string 类中有指针,如果使用了 array new,就一定要使用 array delete,否则类中的指针所指向的空间不会被销毁,就会造成内存泄漏,泄露的不是数组本身,而是类中的指针所指向的内存
- Complex 类中没有指针,其实析构函数没有什么用,但应该养成好的习惯,统一起来,使用 array new 就要用 array delete

- 测试代码
- 一定要写默认构造函数,因为使用 array new 的时候是没有办法设置初值的,调用的就是默认构造函数
- 可以看到地址间隔都是 4 个字节,因为 A 里的数据是 int
- 使用 placement new 设置初值:
new (tmp++) A(i);在 tmp 这个地址创建一个对象 - 处理 array new 的时候是从上往下构建,而 array delete 则是从下往上析构
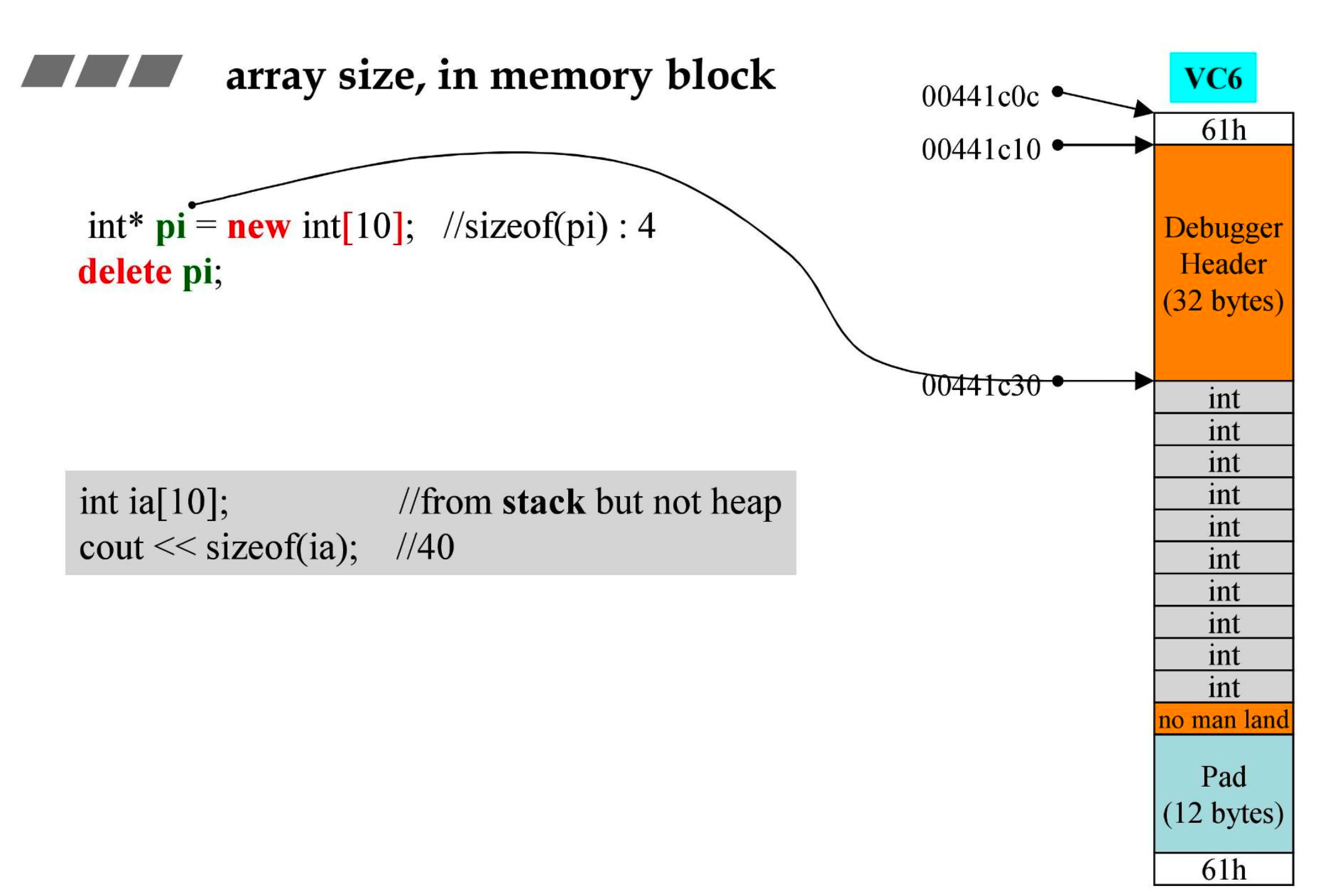
- VC6 下 malloc 的内存布局
- 浅黄色部分在 debug 模式中才会出现(上面有 32 个字节,下面的 no man land 4 个字节)
- 最上和最下的 61h 是 cookie,内存全部加起来是 60h(4+32+40+4+12+4=96),1 代表着这块内存给出去了
- 最后加起来要是 16 的倍数,Pad 就是用来填充到 16 倍数的
- int 并没有析构函数,所以是否使用 array delete 都可以

- 但是如果你放的是 object,而且这个 object 的析构函数是重要的、有意义的,就不一样了,可以看到右侧内存有一块把 array 的大小 3 写了进去
- 每个 Demo 对象里有 3 个 int
# 1.5 placement new

- placement new 允许我们将 object 建构于已经分配的内存中,所以首先需要有一个指针指向已经分配的内存
- placement new 并没有分配内存,内存是之前已经分配好的
- 箭头指向的部分只是
Complex* pc = new(buf)Complex(1,2);的展开。原先 ① 应该是分配内存的,这里变成给它一个 buf,它就传回这个 buf,相当于不做事了,这逻辑是对的 - 从形式上看,
new(p)或::operator new(size void*)就是 placement new
# 1.6 重载
# 1.6.1 C++ 应用程序和容器分配内存的途径

- 讲重载之前先把术语和调用关系梳理一遍
- 转型部分因为不重要从图里去掉了
- 左下角和中间实现是等价的

- 这一页左上角相当于上一页中间的部分
- 容器使用分配器分配内存
# 1.6.2 重载 ::operator new / ::operator delete

- 重载全局的
operator new()、operator delete()和它们的 array 版本
# 1.6.3 重载 operator new / operator delete
# 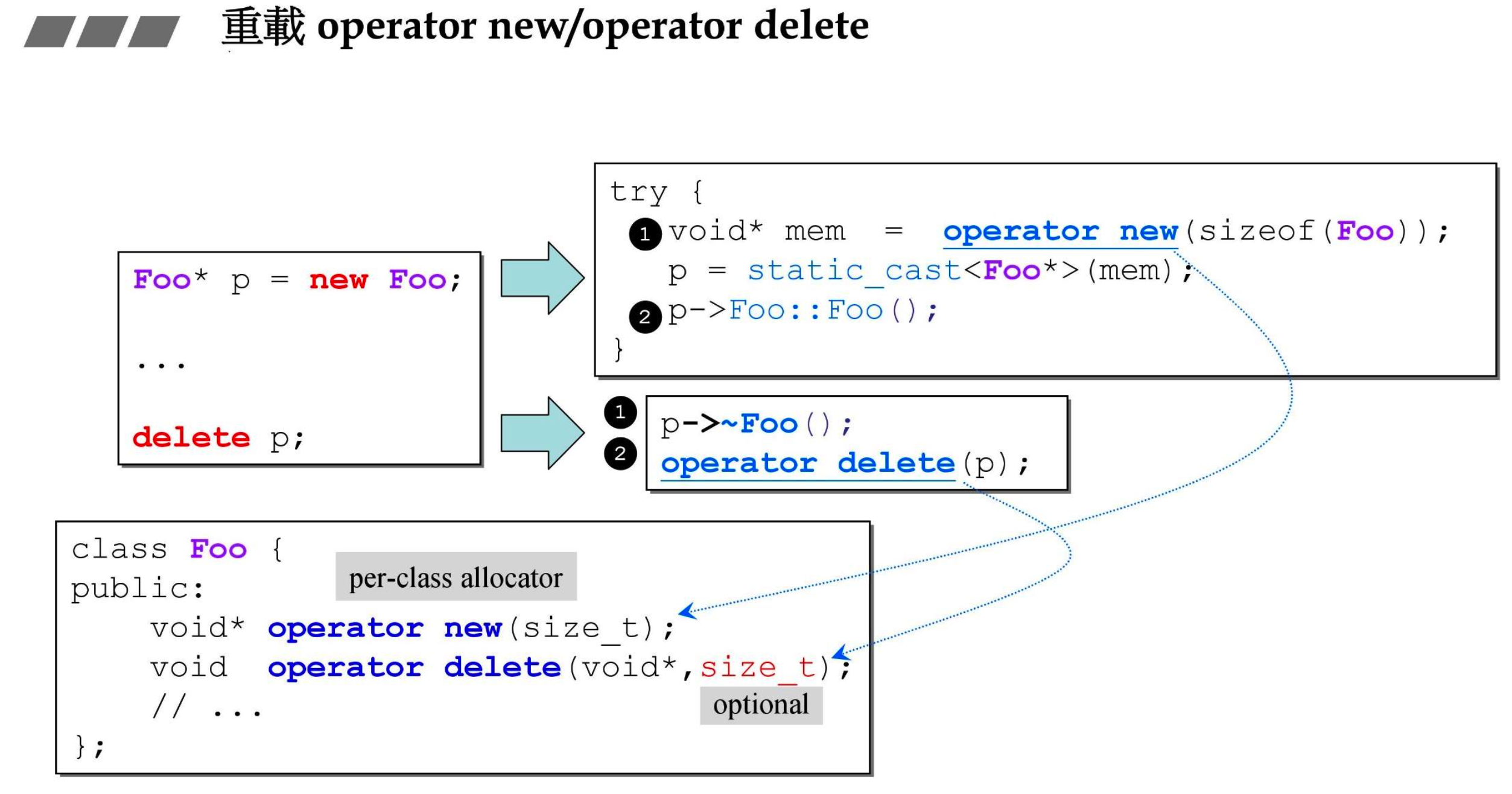
- 在类中重载
- delete 第二个参数是可选的,可以不写,一般也不会写
- 这两个必须是静态的,因为你是在创建对象的过程中调用它们的,可见你手上此时并没有对象,你就没办法通过对象调用它们。但是这里可以不写 static,因为它俩必须是静态的,所以写不写 C++ 都会按照静态处理
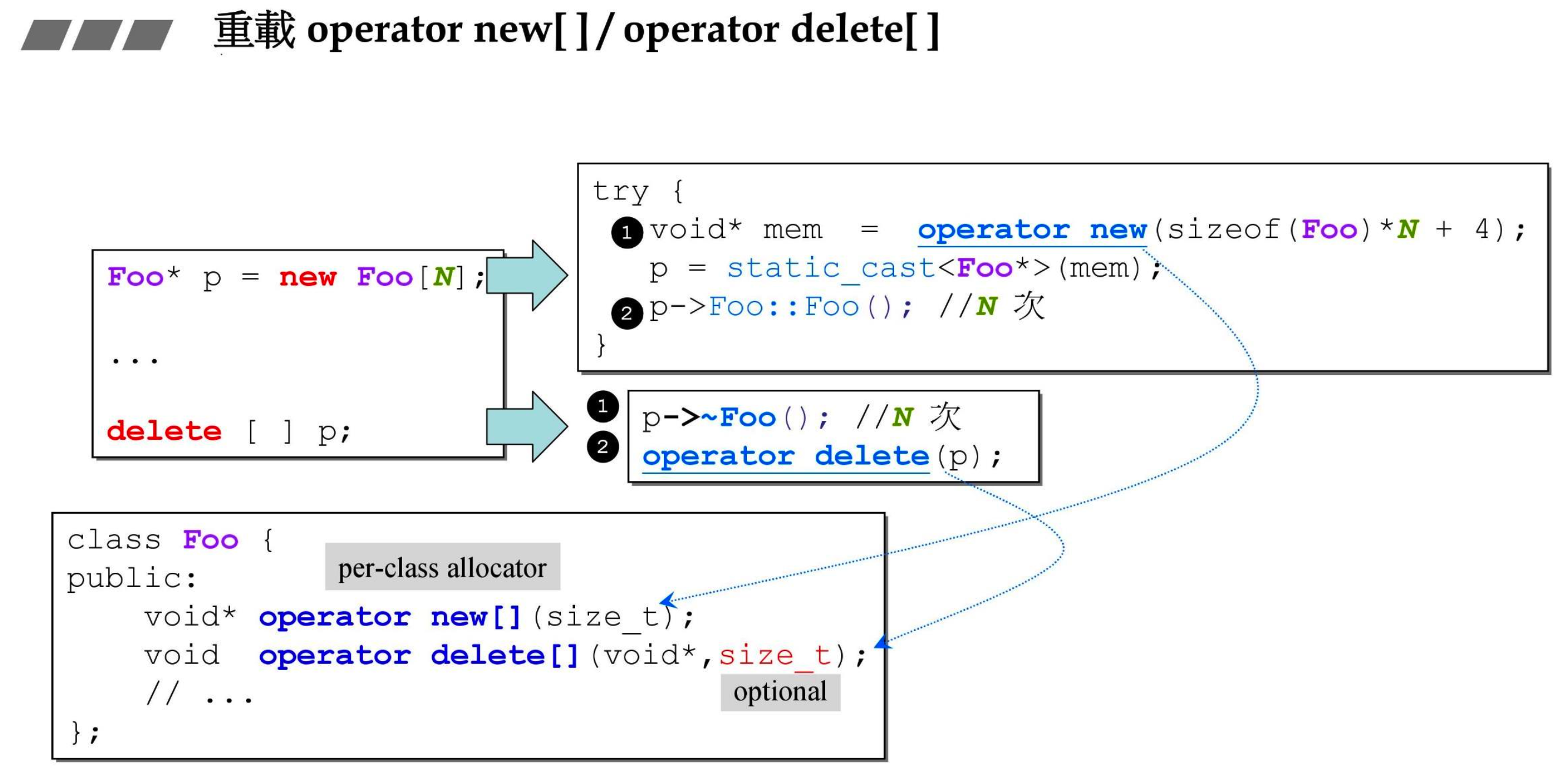
- delete 第二参数依然可有可无
# 1.6.4 重载示例


- 验证这样的写法确实能重载,在重载部分添加了一些输出
- 上面的结果是没有虚函数的 Foo,下面是虚函数的,所以下面比上面大了四个字节

- 写上
::会强制调用全局版本,绕过重载后的函数
# 1.6.5 重载 new() / delete()
:::tips
与《侯捷 C++ 面向对象高级编程(下)》完全相同,下面只做简易笔记
:::

new()里其实可以放不只一个指针,但第一个参数必须是size_t


- 只有在构造函数内抛出异常时,对应的 placement delete 才会被调用,释放掉未完全创建成功的 object 占用的内存

- 每次创建字符串的时候都多带了一包东西,所以需要 extra
# 1.7 allocator
# 1.7.1 per-class allocator

- 目标:减少 malloc 次数,去除 cookie(提高速度,节约空间)
- 为 Screen 这个类写小型的内存管理
- 为了实现我们的设计,增加了一个 next 指针,指向自己(Screen)
- 重载后的
operator new()一次申请能存下 24 个 Screen 的一大块内存,用单向链表串联起来 - 这个内存只针对这个 class 操作,写在这个 class 里,所以把它称为 per-class allocator
- 收回来的指针放入单向链表的头;但是没有还给操作系统

- 测试代码,输出间隔,通过间隔判断有没有 cookie
- 左边是上一页的结果,右边是正常情况的结果,可见右边上下都带了 4 字节的 cookie

- 前面的版本加一个指针带来的额外开销可能比去掉 cookie 节省下来的还要多,这个版本不需要额外加指针
- union 就是同一个东西用不同的名称表现,它里面的两个 member 在同一块。我的数据本来是 8 个字节(unsigned long 4 + char 1 = 5,内存对齐到 8),但我换一个角度,用指针看它,就是四个字节,这种概念叫 embedded pointer(嵌入式指针),所有的内存管理中都用了这种技巧
- 通过指针移动将一大块内存分为 BLOCK_SIZE 块
for (int i = 1; i < BLOCK_SIZE - 1; i++)
newBlock[i].next = &newBlock[i+1]; //next每次移动8个字节
1
2
2
- 收回来的指针同样没有还给操作系统,但你也不能说它是内存泄漏,因为都还在它手上

- 测试代码,可见相比有右侧全局版本,左边依然没有 cookie
# 1.7.2 static allocator

- 之前的写法虽然很好,但如果任何需要良好内存分配的 class 都要在它里面写一个,重复动作太多了
- 把刚刚的动作集中到单一的 class:allocator 中
- 现实中根据经验设置 CHUNK 的大小(标准库是 20)

- 其他类需要用到这种内存管理时,只需要重写
operator new()和operator delete(),然后交给 allocator 去做就好了

- 可以发现,因为操作系统的多线程处理,每次开辟的 5 个元素在内存中都是相邻的,但是这一组元素与另外开辟的 5 个元素不一定是相邻的
# 1.7.3 macro for static allocator

- 我们发现每个 class 的写法都很统一,于是可以转成两个宏
- 设计好之后,只需要在 class 内部用一个宏,外部用另一个宏,就能实现之前的效果

- 换汤不换药,测出来也是一样的
# 1.7.4 global allocator(with multiple free-lists)
# 
- 标准库里的 allocator,可以看做 static allocator 的进阶,不只有一根链表,而是有 16 根链表
- 是全局的,针对所有的 class
- 是第二讲的重头戏
# 1.8 new handler

- C++ 在抛出异常之前一定会先(不只一次)调用你设定的函数,这个函数的形式为:
typedef void(*new_handler)();
new_handler set_new_handler(new_handler p) throw();
//new_handler 可换成自己的函数名
1
2
3
2
3
- 这是为了给用户一个机会,让用户决定内存不足之后怎么办
- 看右侧代码
_callnewh()就是调用到由用户指定的handler - new handler 里应该做什么呢?
- 让更多的内存可用,比方说释放掉一些不影响运行的内存
- 调用
abort()或exit(),让程序结束

- 测试代码,有的版本符合预期,有的版本不行,说明具体行为和平台、编译器有关
# 1.9 =default 和 =delete

- C++11 新加的两个关键字
- 可以在 class 内指定函数是 default 还是 delete。delete 很好理解,就是这个函数不要了。C++ 中只有拷贝构造、拷贝赋值、析构函数有默认版本,default 指的是这个版本(没有默认版本的函数不能用 default)

- 测试
operator new()和operator delete()可不可以设成 default,发现果然不行;而被 delete 的函数也确实不能调用了
# 2.std::allocator
与其自己从头开发,不如学习已有的很棒的东西,所以这里学习标准库中 allocator 的运行模式和源码
# 2.1 VC6 malloc()
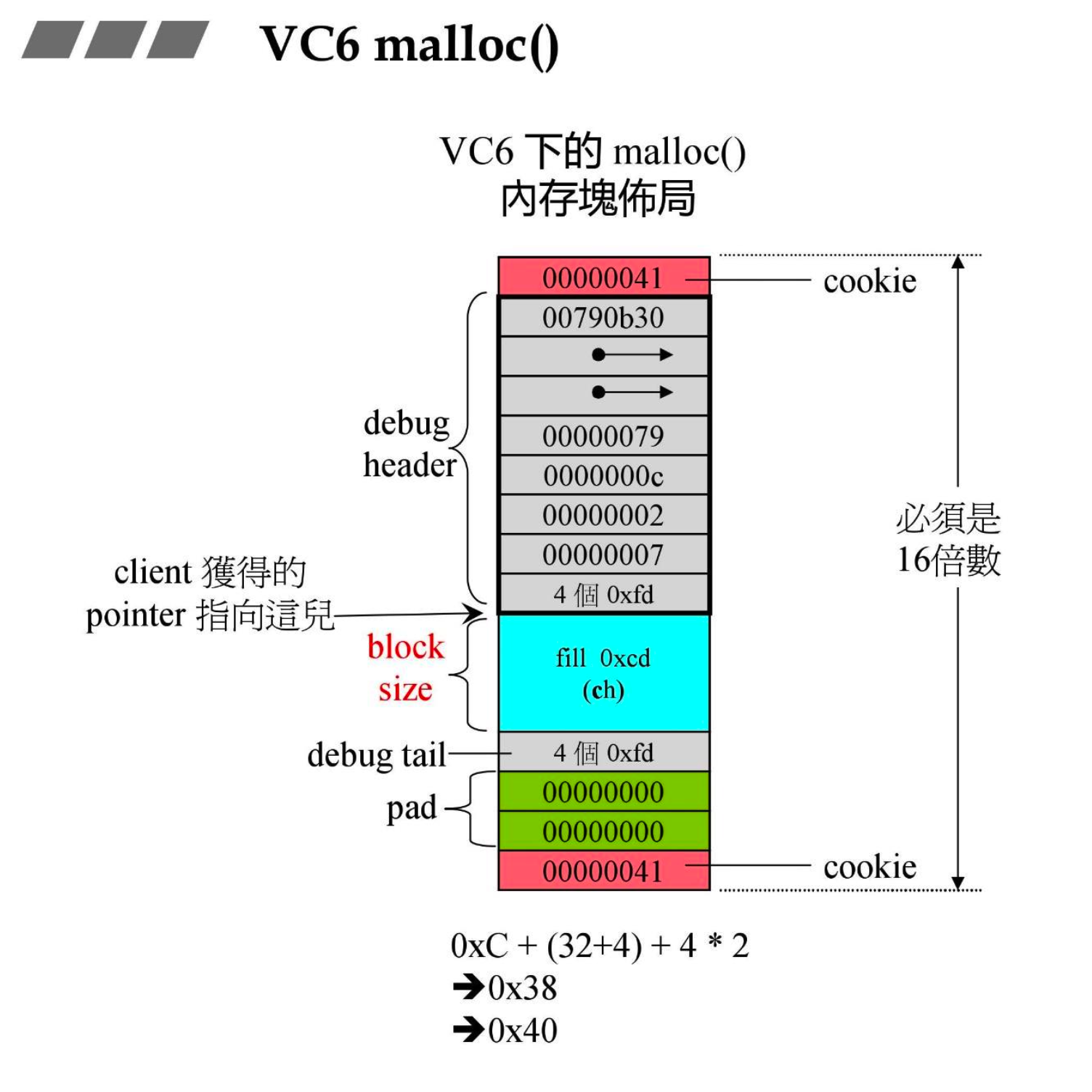
- cookie 主要记录当前分配的内存块的大小
- VC6 下 cookie 占用的大小是 8 个字节
- 假设对象很小,但是对象很多,那么就会有大量的 cookie,消耗了大量的内存
- 内存管理的目标:提高效率,精简空间
- 是否有办法将 cookie 去除呢?
- 去除 cookie 的先决条件就是区块大小相同,如果里面的区块有大有小,cookie 无法记录,而容器中的元素都是一样的大小
# 2.2 不同编译器的标准分配器的实现

- VC6 的 allocator 只是以
::operator new()和::operator delete()完成allocate()和deallocate()。沒有任何特殊设计 - 可见 VC6 没有做任何内存管理,所以也没什么好讲的
- VC6 下使用容器,最终内存分配都是靠
malloc()获得的,而malloc()所分配的内存块中带着 cookie - 此处的分配是以指定的元素的类型为单位,比方说类型指定为 int,分配 512 就是 512 个 int
- 我们很强调容器,因为现在写代码大部分时间都是用容器,所以重视容器的效率

- BC5 的分配器也是什么特殊操作都没有,和刚刚的 VC 完全一样

- 和 VC 和 BC 一样,GCC 2.9 也没有做额外设计
- 右下角注释表明,容器用的并不是这个

- 容器使用的是
std::alloc - alloc 是个 class,
alloc::allocate说明allocate()是 alloc 这个类的静态函数 - 可以发现,分配时是分配 512 个字节,而不像前面一样分配 512 个元素。


- 到 GCC 4.9,换了名字和一些变量名,不再在编制之内,其实就是之前的那个东西
- GCC 2.9 用法:
vector<string, std::alloc<string>> vec; - GCC 4.9 用法:
vector<string, __gnu_cxx::__pool_alloc<string>> vec;

- 标准分配器说的是
std::allocator - 也是没有任何特殊设计

- 所以我们来学习好的做法
- pool_allocator 去除掉了 cookie,100 万个元素,就能省掉近 800 万个字节
- 测试代码
- 使用 pool_allocator ,一个 double 8 个字节,现在我连续分三块,它们距离是 8 个字节,可见每块真的不带额外开销
- 使用 std::allocator,得到的三根指针相距 16 个字节,说明额外加上了上下 cookie 共 8 个字节
- 某一次使用 pool_alloc 的结果,指针之间相差不是 8 字节,并不能推翻分配的内存块不带 cookie 这个结论,因为是进行了 3 次分配,可能分配的内存块并不连续
# 2.3 std::alloc
# 2.3.1 总图

std::alloc是我们学习的目标- 分配器一定要提供两个重要的函数:
allocate()(分配)和deallocate()(回收) - 16 条链表,超过这个链表最大管理的内存块大小范围(128 字节)的内存分配不再受
std::alloc管理,而是通过malloc()进行分配 - #0 串联 8 字节的内存块,#1 串联 16 字节的内存块,#2 串联 24 字节的内存块… 链表间的内存块相差 8 字节
- 如果容器中的每个元素需求的内存块的大小不是 8 的倍数,比如需要 6,则进入
std::alloc这个系统后,会被调成 8;这个设计在所有的分配器上都一样,malloc()也是这样的设计,一定会调整为设定好的边界 - 如果声明一个 vector,每个元素的大小都是 32 字节。#3 是管理 32 字节的内存块的,一开始 #3 是空的,它就会去挖(
malloc())一块 2032 大小的内存以备使用(20 应该是开发std::alloc的人员的经验值);当这 20 块 32 字节的内存使用完之后,又会再要 2032 字节大小的内存,以此类推 - 实际上挖的大小是 20232 字节,其中一半拿来切 32 字节的内存块,另一半空置等待使用
- 声明另一个 vector,每个元素的大小是 64 字节。需要 #7 链表来管理 64 字节的内存块,当 #7 链表需要的时候,将剩余的 20*32 切割成每个内存块 64 字节的大小,可以切出 10 个,可以看到它们 #3 和 #7 的内存块是相连的;至此,分配的内存都使用完了
- 再声明一个 vector,每个元素的大小是 96 字节。#11 是管理 96 字节内存块的,此时它是空的,而且之前 #3 多分出来的也都用光了,于是
malloc()20962 字节内存,一半拿来用,一半备用 - 容器不再需要元素的时候,要归还内存,根据内存大小就回收到负责该大小的内存块的链表上
- 如果容器中的每个元素的大小为 256 字节,超出了链表的内存块的范围(8~128),于是调用 malloc 进行分配,将分配得到的空间传回给容器
- 容器每次动态分配得到的都是指针,它并不会知道分配到的内存是否带 cookie
- 最初分配的 202x 的一大块是
malloc()出来的,带 cookie,但std::alloc管理的内存块都是 cookie free 的

- 链表借用每个内存块的前 4 个字节做指针,当把内存块分给容器后,这 4 个字节会被容器的数据填充,容器归还内存块后,分配器会重新把前 4 个字节用作指针,接到链表上。这种做法称为 embedded pointer(嵌入式指针)
- 好的内存管理一定会使用嵌入式指针,否则 class 里还要多设计一个指针(见 1.7.1 的版本 1)
- 源代码中的
char client_data[1];并没有用到,可以删除,删掉后是 union 还是 struct 就没区别了 - 如果对象本身小于 4 个字节,就不能被借用作指针了。但是通常对象大小会大于等于 4 字节
# 2.3.2 分步骤讲解

- 一开始,定义了
free_list[16]
# 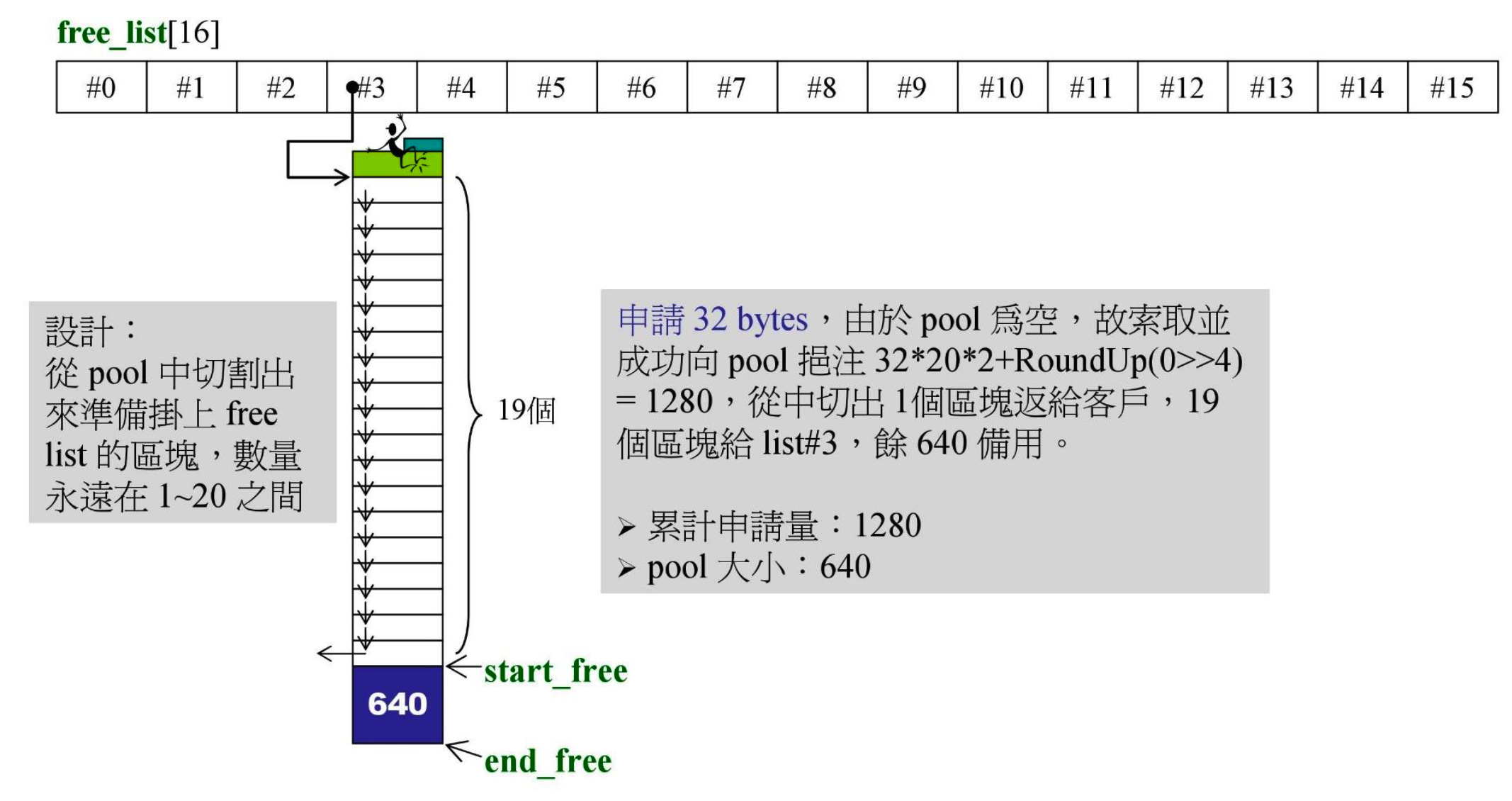
- 容器申请了 32 字节
- pool 指的就是之前说的多出来的备用空间,我们可以称它为战备池,由 start_free 和 end_free 两个指针围起来。平时说内存池(pool)指的是整个空间,这里只是蓝色的那个部分,注意区分。
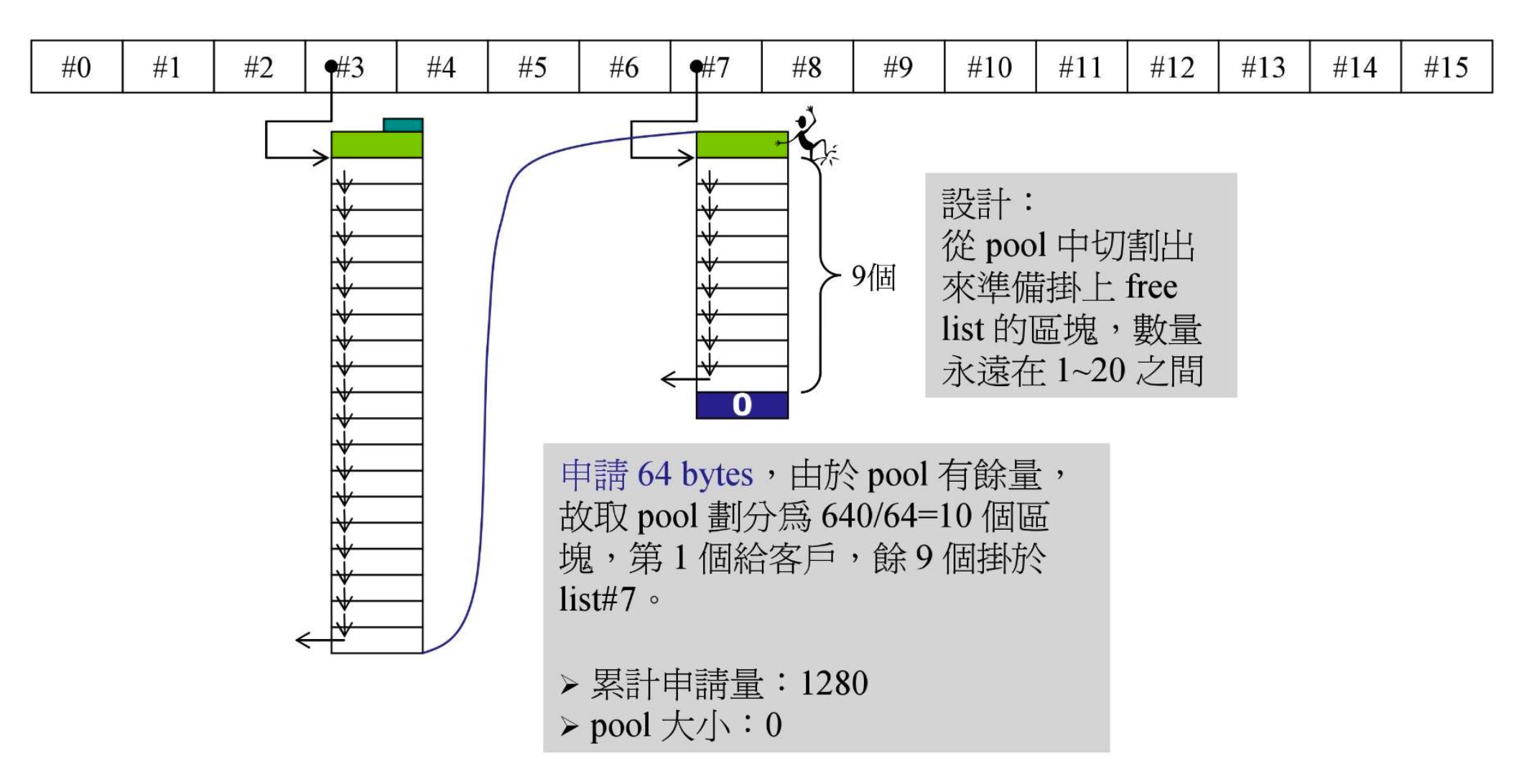
RoundUp()的作用是把数字上调到 8 的倍数,0>>4 指的是 0 右移 4 位,即 0 除以 16。RoundUp(0>>4) 结果是 0,这部分我们可以称为“追加量”- #3 是空的,先看 pool 有没有,发现也是空的,于是给 pool 申请 32202+RoundUp(0>>4)=1280 的空间。640 给客户,另一半 640 备用(pool)
- 这一整块是用
malloc()分配的,头尾都有 cookie
- 另一个容器申请 64 字节,因为 pool 有余量,所以从 pool 中切出 10 个
- 因为是同一块,所以没有产生额外 cookie
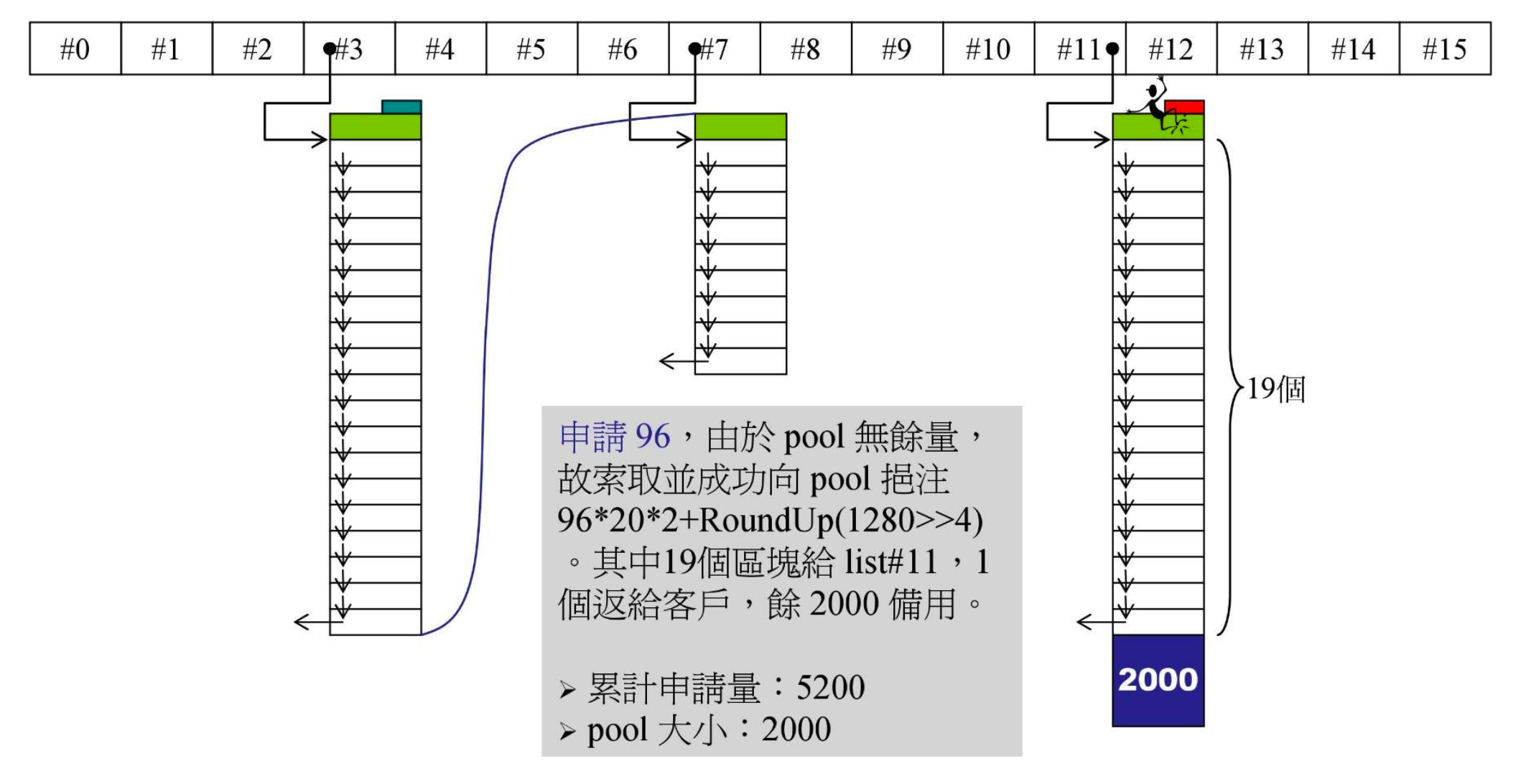
- 又有一个容器申请 96 字节
- pool 是空的,用
malloc()分配 96202+RoundUp(1280>>4)=3920,分出 20*96=1920,pool 留下 2000,这一大块是带 cookie 的 - 这里可以看出追加量的计算方式,
RoundUp()里是累计申请量>>4,即累计申请量/16,发现追加量会越来越大。为什么会有追加量,以及为何如此计算,源码的注释中并没有解释,不过这样的处理带来了安全阀门(后面讲解)

- 又有一个容器申请 88 字节,pool 中有余量,分出 20 个(哪怕 pool 还有更多,最多也只能分出 20)。
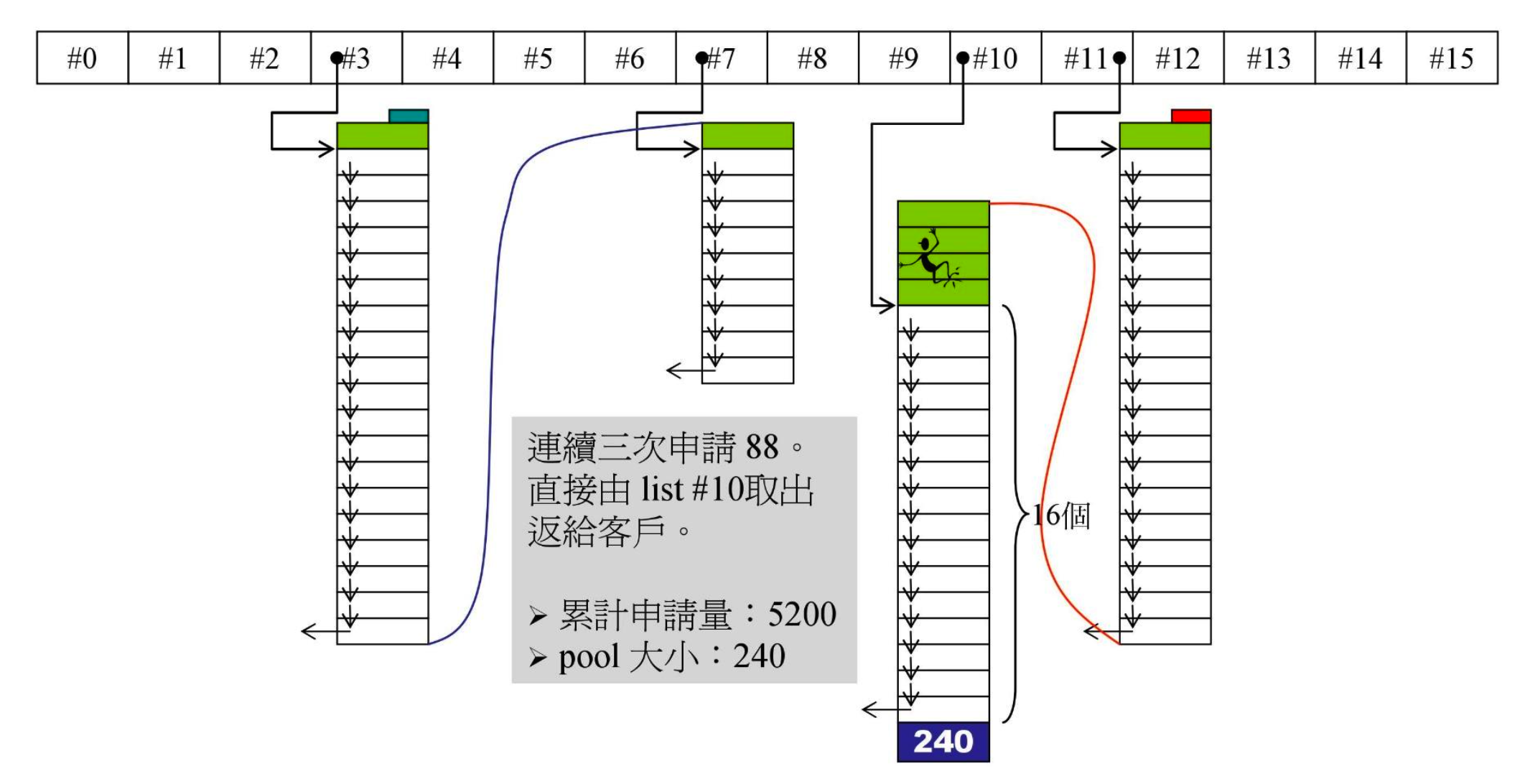
- 不再新建容器了,而是某个容器连续三次申请 88
- 直接取出 3 个返回给容器,速度很快
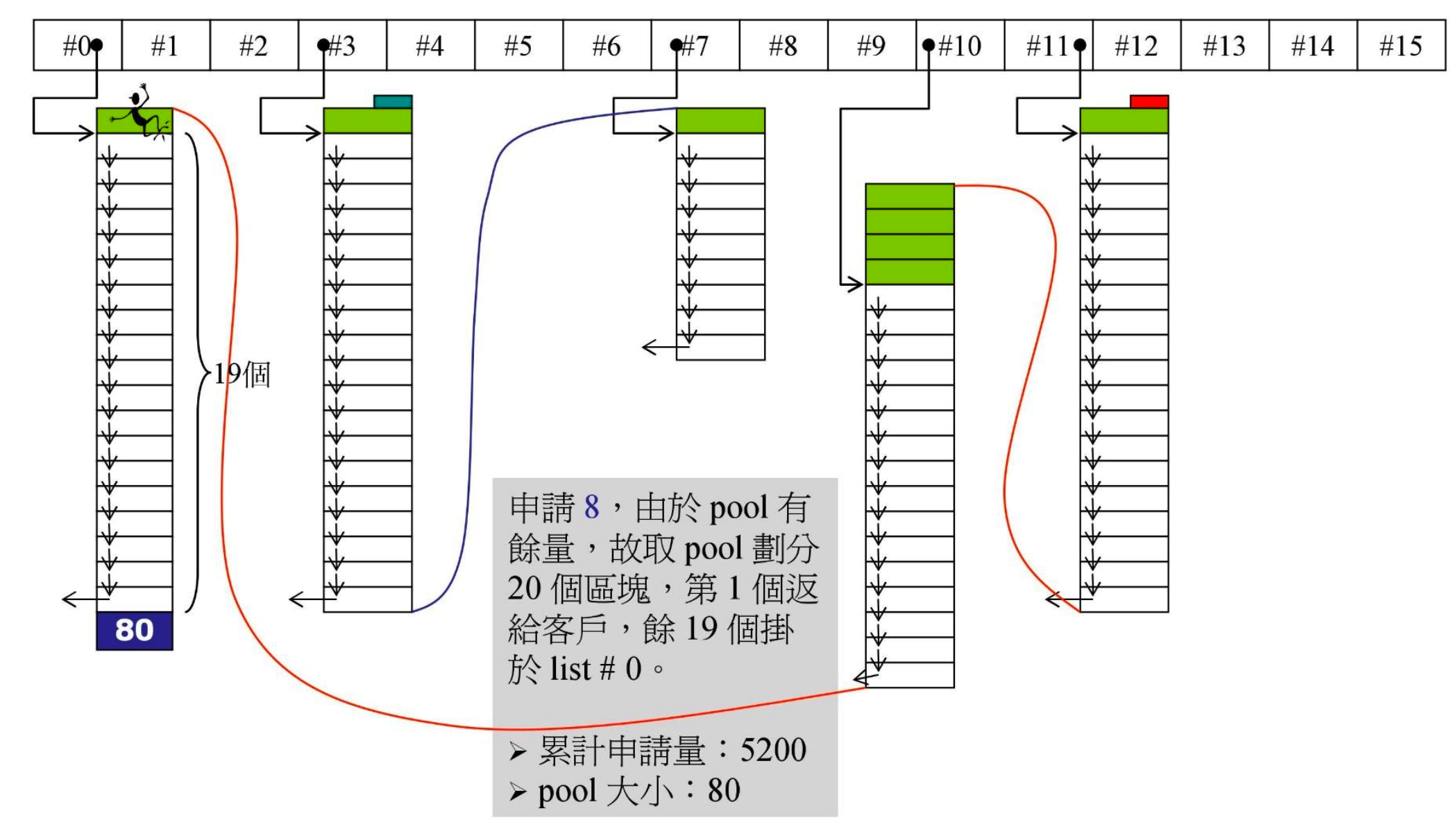
- 又有一个容器申请 8 字节,pool 中有余量,分出 20 个
- 如果不同的容器(vector、list、deque……)大小相同,会共用同一条链表
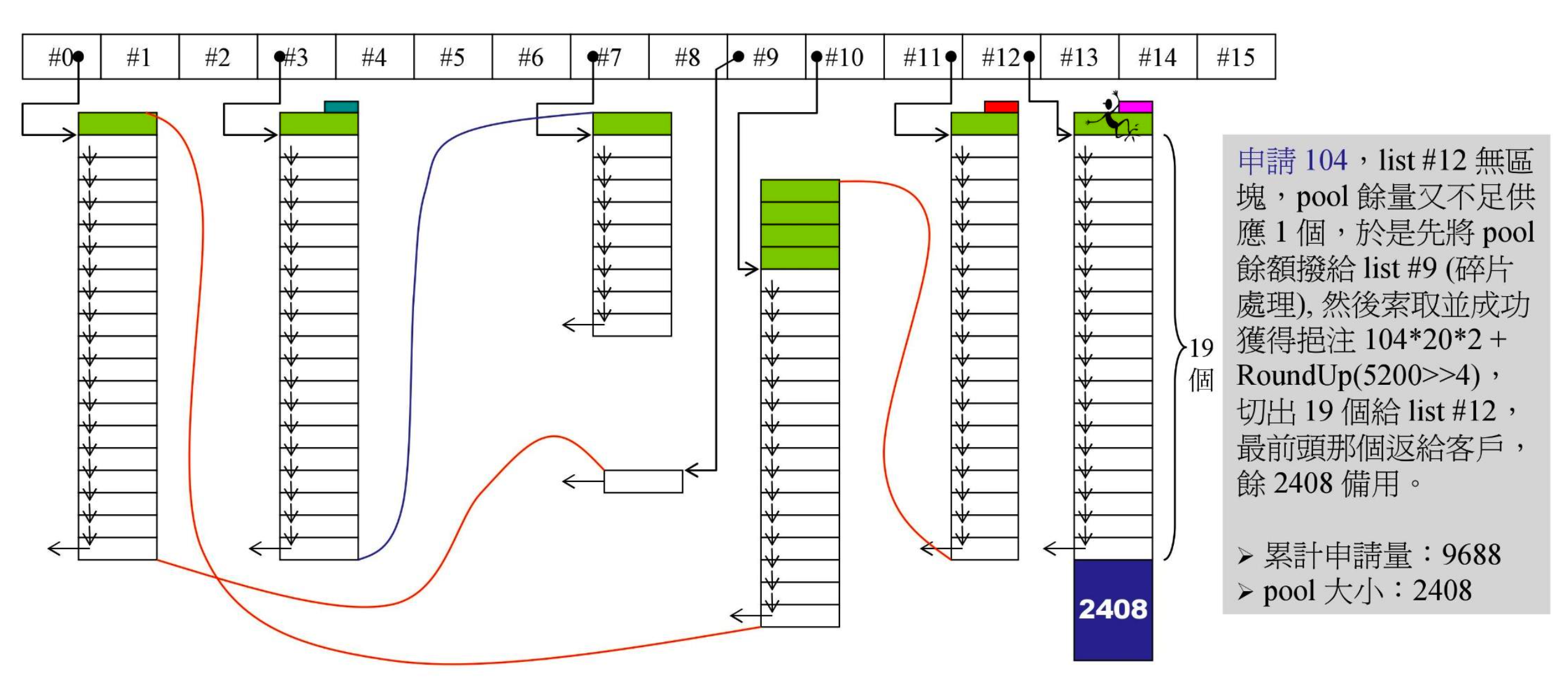
- 又有一个容器申请 104 字节
- pool 只有 80,连 1 个都不够,这 80 便是内存碎片,需要先处理碎片
- 80 归 #9 管理,所以处理方式就是把 80 拨给 #9
- 然后
malloc()分配 104202+RoundUp(5200>>4)=4488
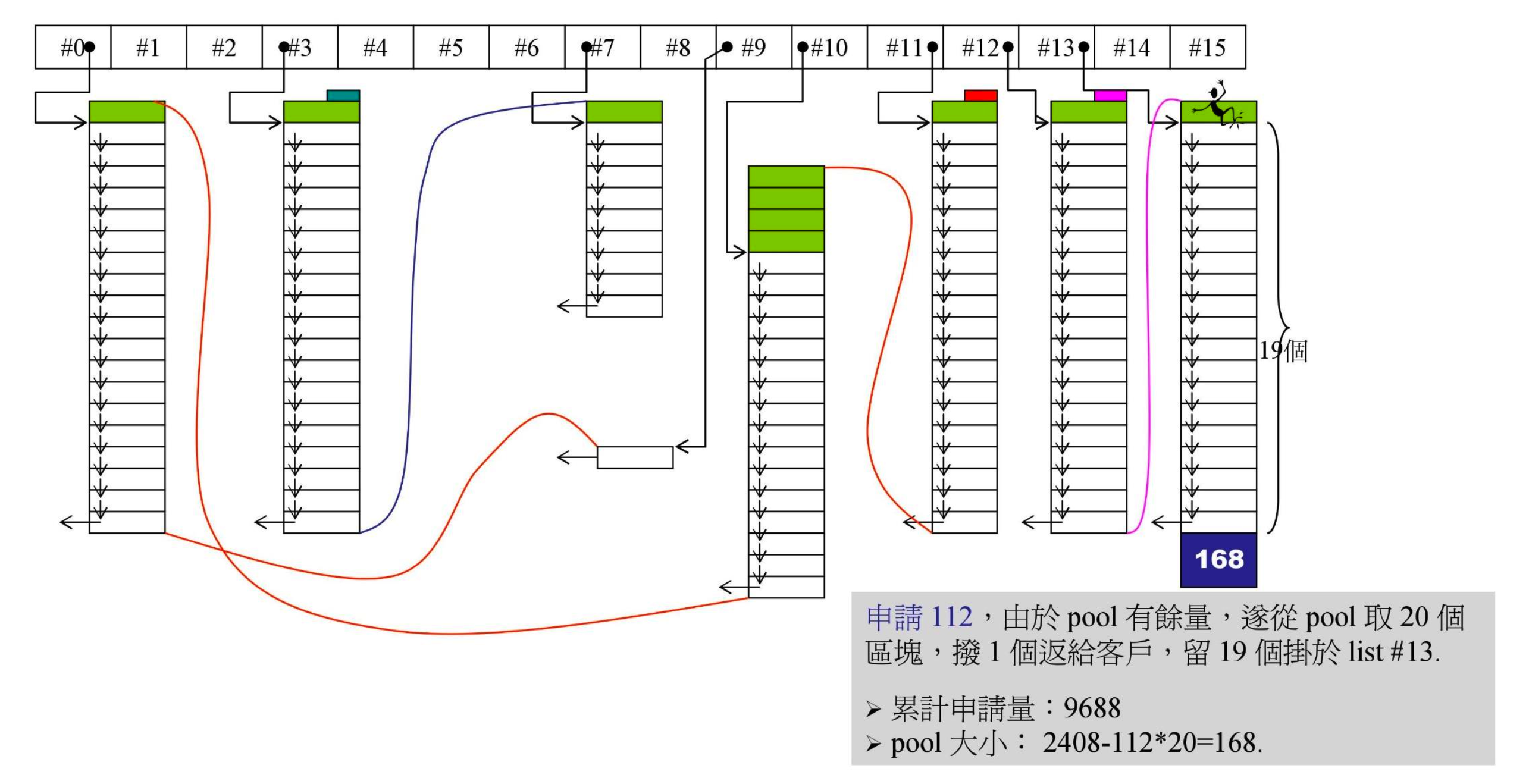
- 又有一个容器申请 112 字节,pool 中有余量,分出 20 个
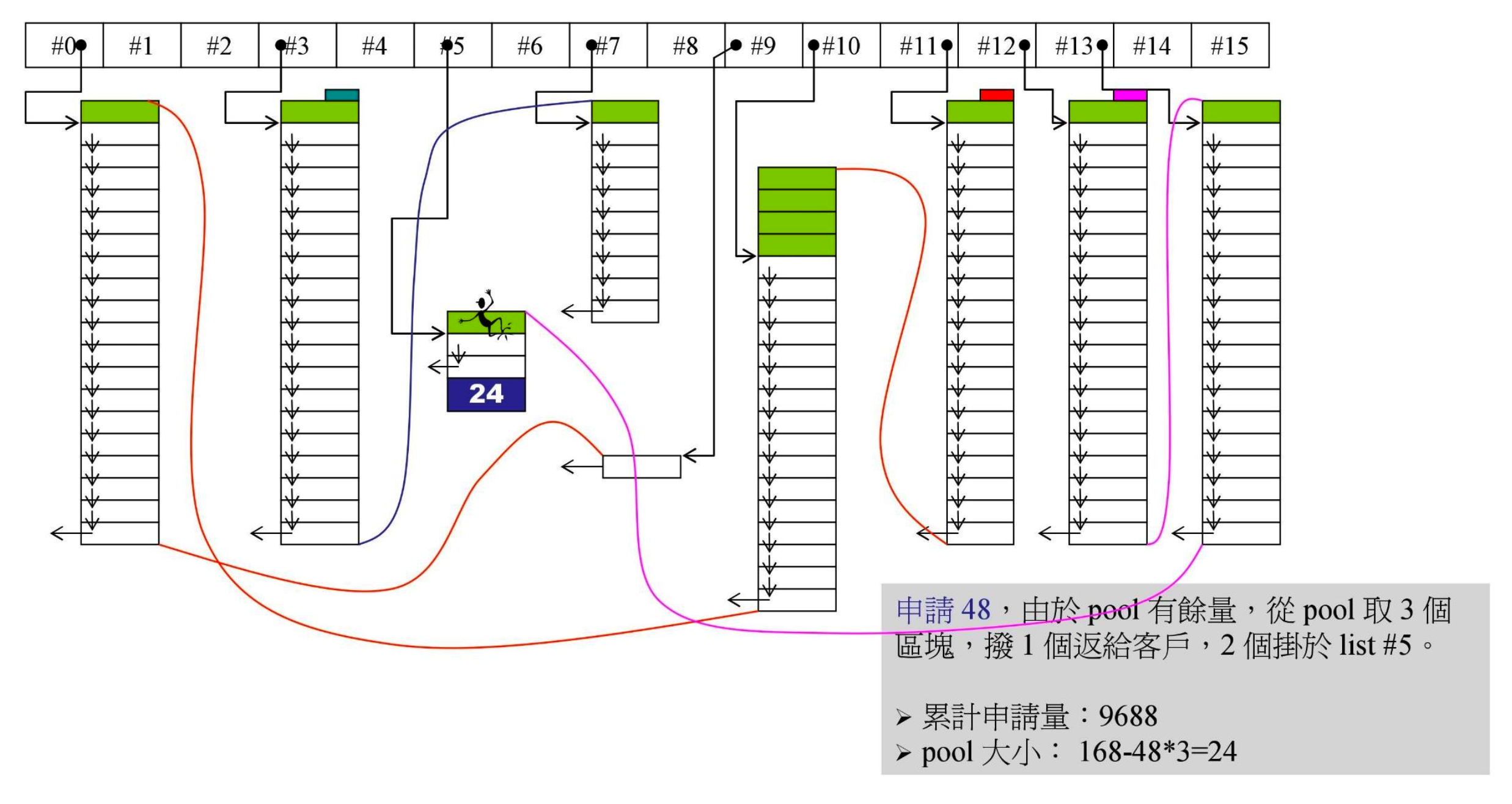
- 又有一个容器申请 48 字节,pool 中有余量,分出 3 个。
以上步骤把所有可能的情况都列出来了,下面看一下内存耗尽的话会发生什么

- 为了测试,将系统内存大小设置为了 10000,而现在已经申请了 9688 了
- 又有一个容器申请 72 字节
- pool 只有 24,是碎片,这 24 挂到 #2
malloc()分配 72202+RoundUp(9688>>4),因为内存不足,malloc()失败- 为了满足用户需求,从 #8 右侧找离 #8 最近的,发现 #9 有一个 80,于是从 80 中切出 72 给 #8,剩下 8 作为 pool,#9 变为空

- 又有一个容器申请 72 字节
- pool 只有 8,分给 #0
- 从 #10 中拿出一块,72 给 #8,剩下 16 作为 pool

- 又有一个容器申请 120 字节
- 从 #14 右边找,发现右边的 #15 也是空的,山穷水尽,无法满足需求

- 如果要把小块合并:因为都是链表,指来指去的,很难找到相邻的两块或几块合并,而且链表长度也不确定,虽然理论上可行,但难度极高,其他分配器也没有实现这样操作的
- 如果要把系统剩下的 312 用光:比较简单,
malloc()失败的话,就把malloc()内的数值减半,直到成功,但 GCC 并没有这么做,后面会给出答案
# 2.3.3 源码剖析



- 这是第一级分配器,前面讲的步骤都在第二级分配器中,如果第二级分配器分配失败就会来到第一级
- 第一级会模拟 new handler(1.8 讲过),不断循环给用户机会去分配
- C++ 本来就有 new handler,没必要模拟,这里这么写可能是因为历史元素,GCC 4.9 就没有这个第一级分配,所以此处也跳过,不详细讲解
- 第一级分配器到 74 行截止。77~89 是换肤工程,第二级分配器的单位是字节,换肤工程可以把字节转换为元素的个数。

- 第二级分配器从 90 行开始。为了教学,多线程的部分都被拿掉了。
- 三行 enum 其实就是常量定义,因为历史原因没有写成 static const
ROUND_UP()会将传入参数上调为 8 的倍数- union obj 是嵌入式指针,free_list_link 其实就是我们平时常写的 next
- 所有的数据和函数都是静态的,可见非常容易改写为 C 语言
FREELIST_INDEX()计算出申请的内存块应该由第几号链表提供;refill()就是当链表为空的时候,要进行充值(即申请一大块内存);chunk_alloc()申请一大块内存;

- 最重要的
allocate()和deallocate() - my_free_list 是指针的指针,因为它指向 16 条链表的其中一个,而里面的元素又是个指向下面链表的指针
- 如果申请的内存的大小大于 128,就改用第一级分配器
my_free_list = free_list + FREELIST_INDEX(n);表示定位到第几号链表- 如果 result == 0 ,即链表为空,则需要充值;
- 如果不为空,便
*my_free_list = result->free_list_link;将第一块内存块给到用户,并向下移动指针; deallocate()接收指针,并把它还回链表。如果 n>128 也会改用第一级去回收- 两个问题
deallocate()没有将内存还给操作系统(free),而是将申请到的内存全部掌握在自己手中,不算内存泄露,但是这种做法是有争议的deallocate()并没有检查传入指针是不是这个 alloc 给出去的,如果这个指针指的大小不是 8 的倍数,可能会有灾难性的后果
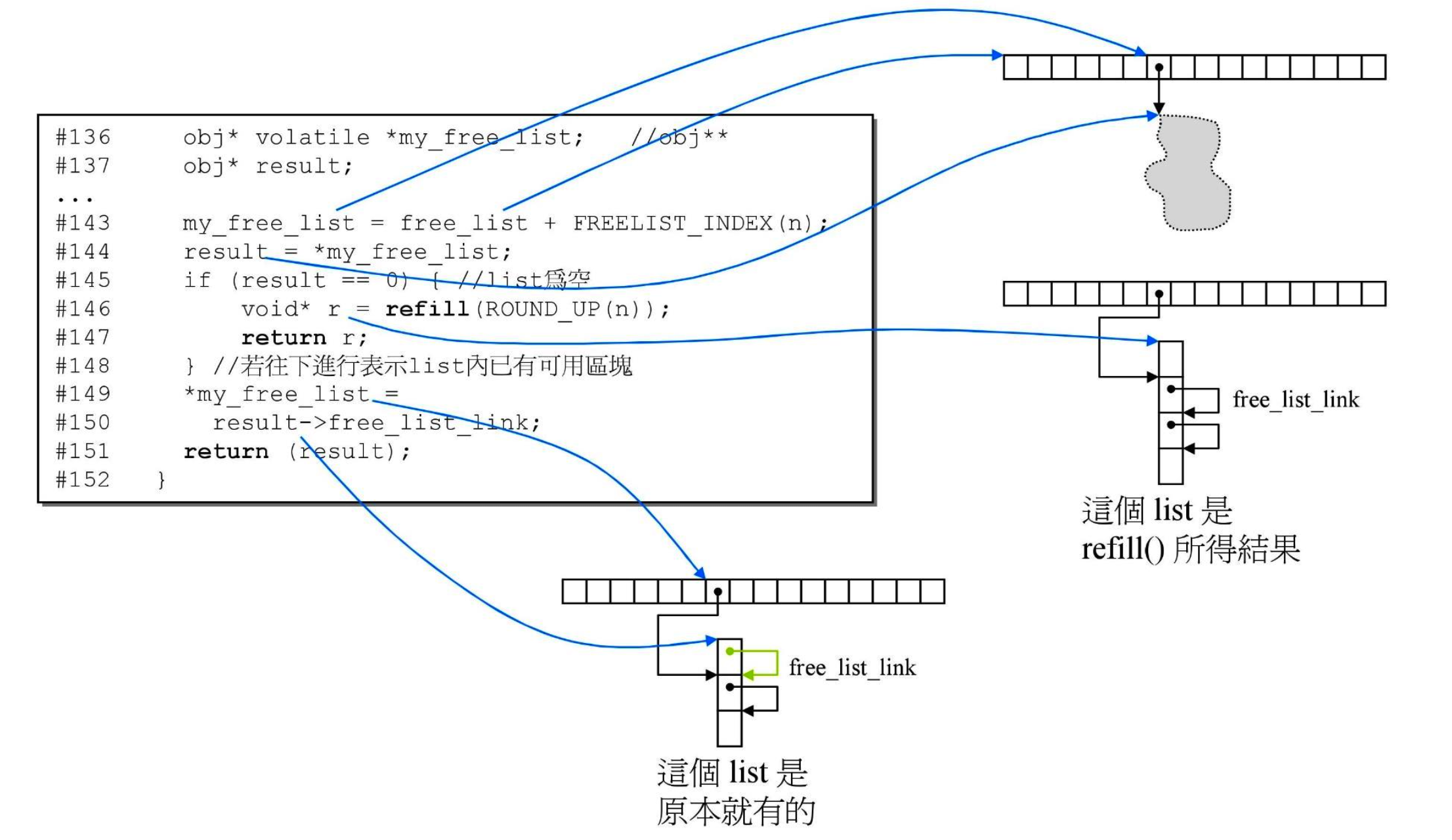
- 通过图片更好地展示上面代码的作用

chunk_alloc()负责帮我们分配一大块区域- total_bytes 是 20 个的大小,bytes_left 是 pool 的大小
- 如果 pool 足够分出 20 个,就直接改 start_free 的位置,然后把 start_free 原先位置传回去
- 如果不够 20 个,但够 >= 1 个,看够几个,然后分配
- 如果连 1 个都不够,就是 0 或碎片了,对碎片做处理

- 处理完碎片后 pool 为空,开始分配内存,让 start_free 和 end_free 指到对应位置,然后递归调用自己,因为 pool 大小足够了,所以肯定能满足要求,完成分配
- 如果
malloc()失败,找右边的链表,拿出一块,放到 pool 中,然后再递归调用自己,完成分配 - 英文注释部分说明了为什么没有再申请更小的内存,后面 2.3.4 检讨部分会解释
- G4.9 中 start_free 是通过 operator new 进行分配的,而非 malloc,所以可以重载 operator new 接管内存分配,这就是为什么我们在 2.4 节是用 4.9 版测试的

refill()函数- 20 是个 magic number,不大好,最好是写成常量或宏
- 交给
chunk_alloc()去拿一大块内存 - 如果只有一个,直接返回,否则就建立自由链表
- 注意 for 循环是从 1 开始的,因为第一个要给出去,没必要再切割、链接
- 所谓切割就是把指针所指处转为 obj*(嵌入式指针)
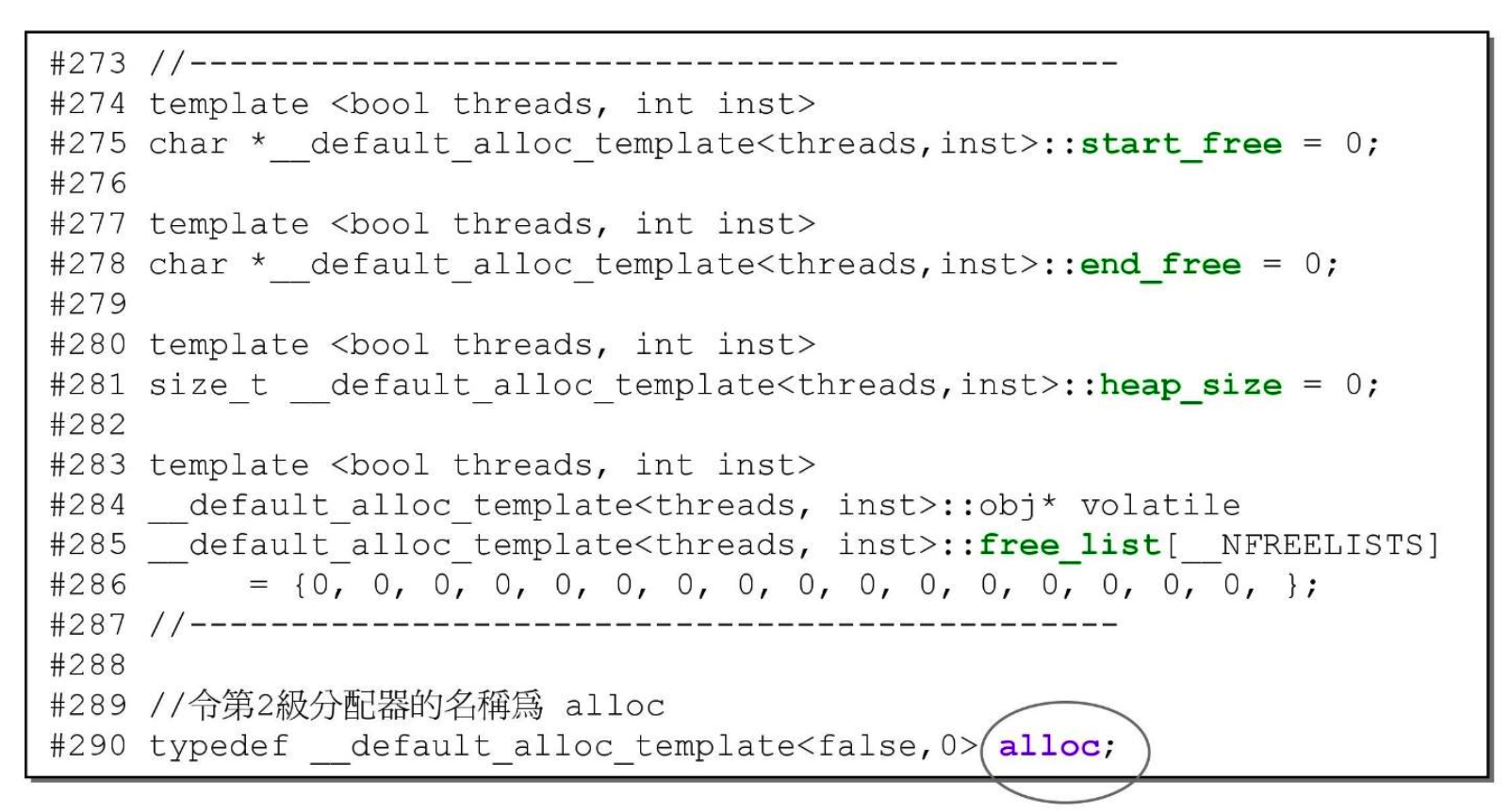
- 因为数据是 static 的,所以需要在 class 外部定义
# 2.3.4 观念整理与检讨
# 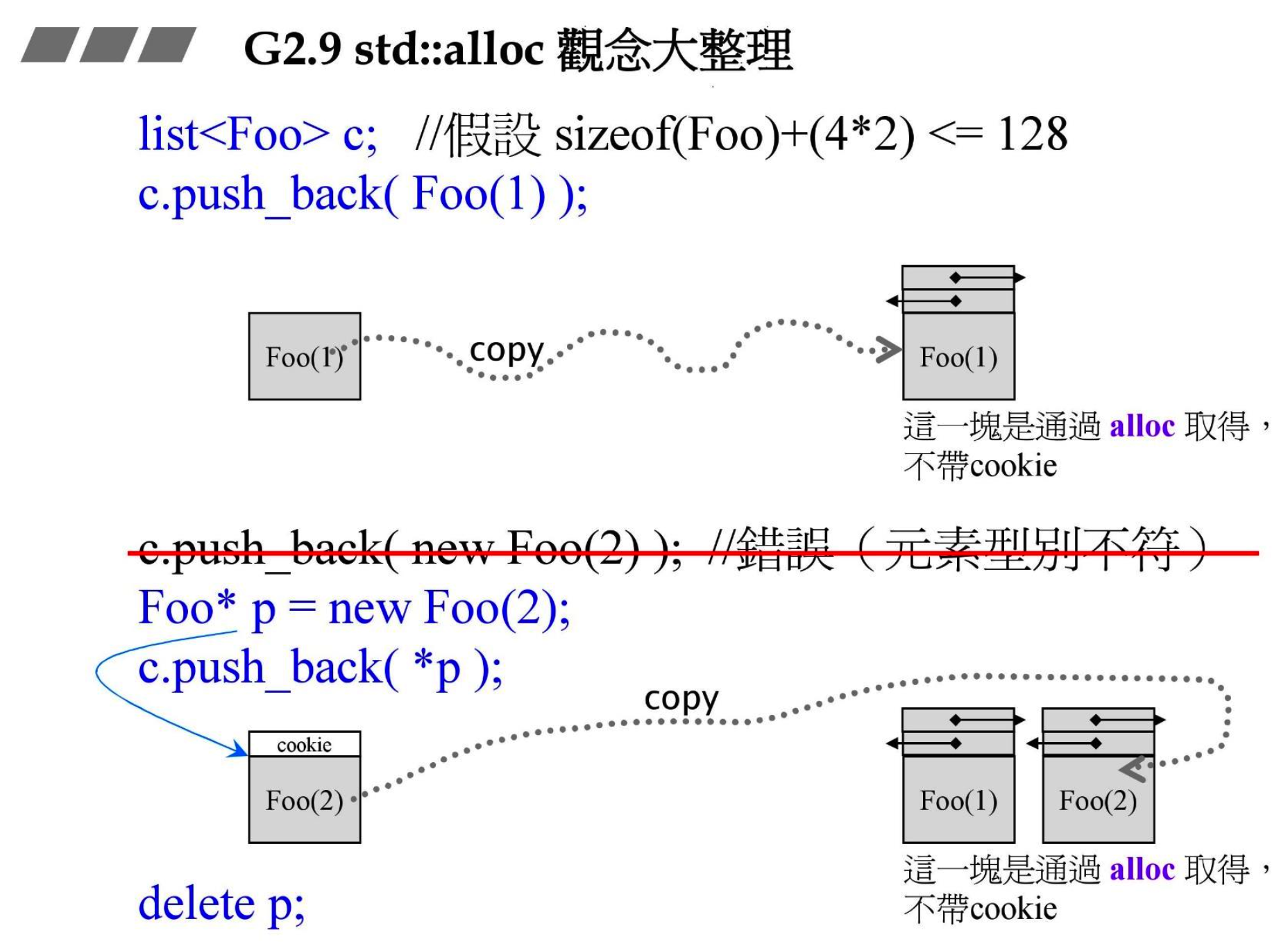
- Foo(1) 是个临时对象,非动态分配的,存在于 stack,容器 c 的内存是通过 alloc 分配的,不带 cookie
- new 底层是通过
malloc()分配的,存在于 heap,分配的内存块带 cookie。push_back()到链表后也是不带 cookie 的。

- 208、218、255 行是数值比较,一般的习惯则是把变量写左边,把要比较的值写右边,这里之所以反着写,是因为如果把变量写左边,哪怕 == 写成 = 也会通过编译,数值写左边的话编译器可以帮我们找出问题
- 197 行的变量一直到 207 行才用到,中间做了许多操作,这样不好,应该把变量写到 206 行。因为如果是指针的话,中间的操作可能会使指针失效,出了问题后难以排查
- 136 和 210 行不用管 volatile。
obj* *my_free_list, *p;的意思是obj** my_free_list和obj* p,所以它这种写法很容易搞错,建议分开写 - 34 行的内容等同于右边框里的两行,硬要把这两行写成一行,纯属炫技,可读性差
- 212、213、214 行说如果尝试申请小内存,会在多进程机器上造成大灾难,意思不是说这个程序会怎么样,而是如果把内存都占用光,机器上的其他程序会没有内存可用
deallocate()没有调用free()或delete(),源于其设计上的先天缺陷:交给客户的内存块没有指针一直记录着其地址,所以归还的时候不知道地址,就无法回收。后面第四部分讲 Loki allocator 时会处理这个问题
# 2.4 G4.9 pool allocator 运行观察

- 为了测试是否真的节省了 cookie,编写测试代码,通过重写 operator new/delete 统计总分配量和总释放量
- 右边为什么 (1) (2) 可以并存老师也不知道

- 右侧 lst 默认使用的是标准分配器,每个元素都带 cookie。double 占 8 字节,每个节点带两个指针,一个元素就是 16 字节,
push_back()1000000 次,总共执行了 1000000 次malloc(),分配了 16000000 字节,这 1000000 次每次都带 cookie - 左侧 lst 使用的分配器为 __pool_alloc,
push_back()1000000 次,总共只执行了 122 次malloc(),分配了 16752832 字节,122 次每次都带 cookie,可见差距之大 - 不能观察到 malloc 真正分配出去的总量(含所有 overhead),因为 malloc 不能重载,除非你有很高的技巧,清楚地理解了 malloc 的行为模式,理解了它管理的每个区块其实是个链表,知道了链表的头,遍历一遍,就能得到内存块的大小。第三讲我们会为大家建立起这种能力
# 2.5 G2.9 std::alloc 移植至C

- 很简单
# 3.malloc/free
# 3.1 VC6 和 VC10 的 malloc 比较
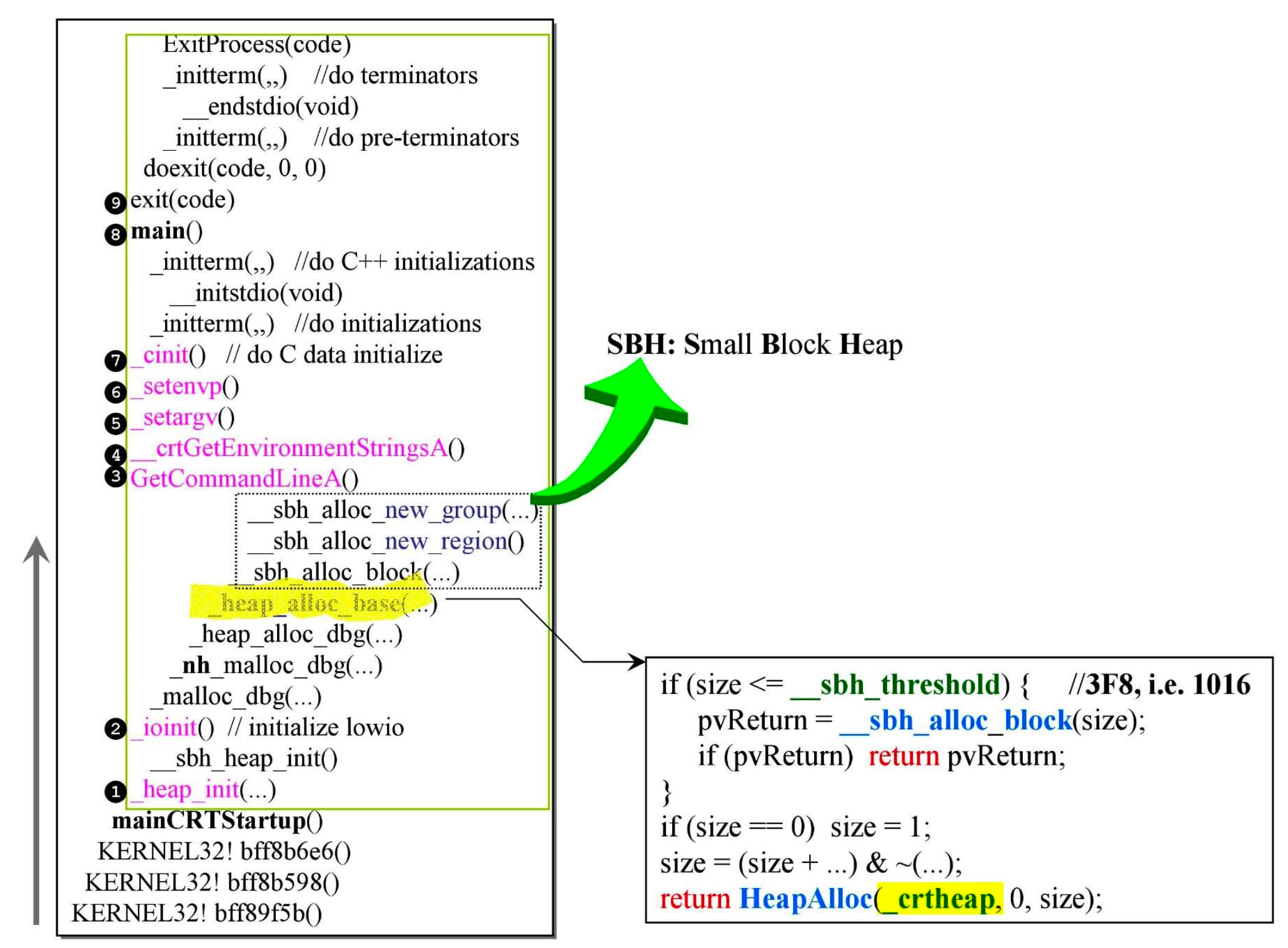
- VC6 内存分配
- 左边的图是 core stack,调用栈,展现了 C++ 程序进入之前和之后的行为(进入点是 ⑧main())
_heap_alloc_base()进行了小区块的阈值判断,小于等于 __sbh_threshole(数值为 1016) 使用__sbh_alloc_block()进行内存分配,否则使用 Windows 系统函数HeapAlloc()进行内存分配

- 划掉的是 VC10 中不存在的部分
_heap_alloc_base()函数没有对小区块的阈值判断了,而是统一使用系统函数HeapAlloc()进行内存分配- 可见 VC10 中没有 SBH 相关操作,不再为小块内存做特殊管理
- 原因是相关操作都由操作系统的
HeapAlloc()实现了
# 3.2 SBH(Small Block Heap)

HeapCreate()也是 Windows 的 API- 初始化操作就是分配了 16 个 header(如果后面 16 个 header 用光了会再新建 16 个)
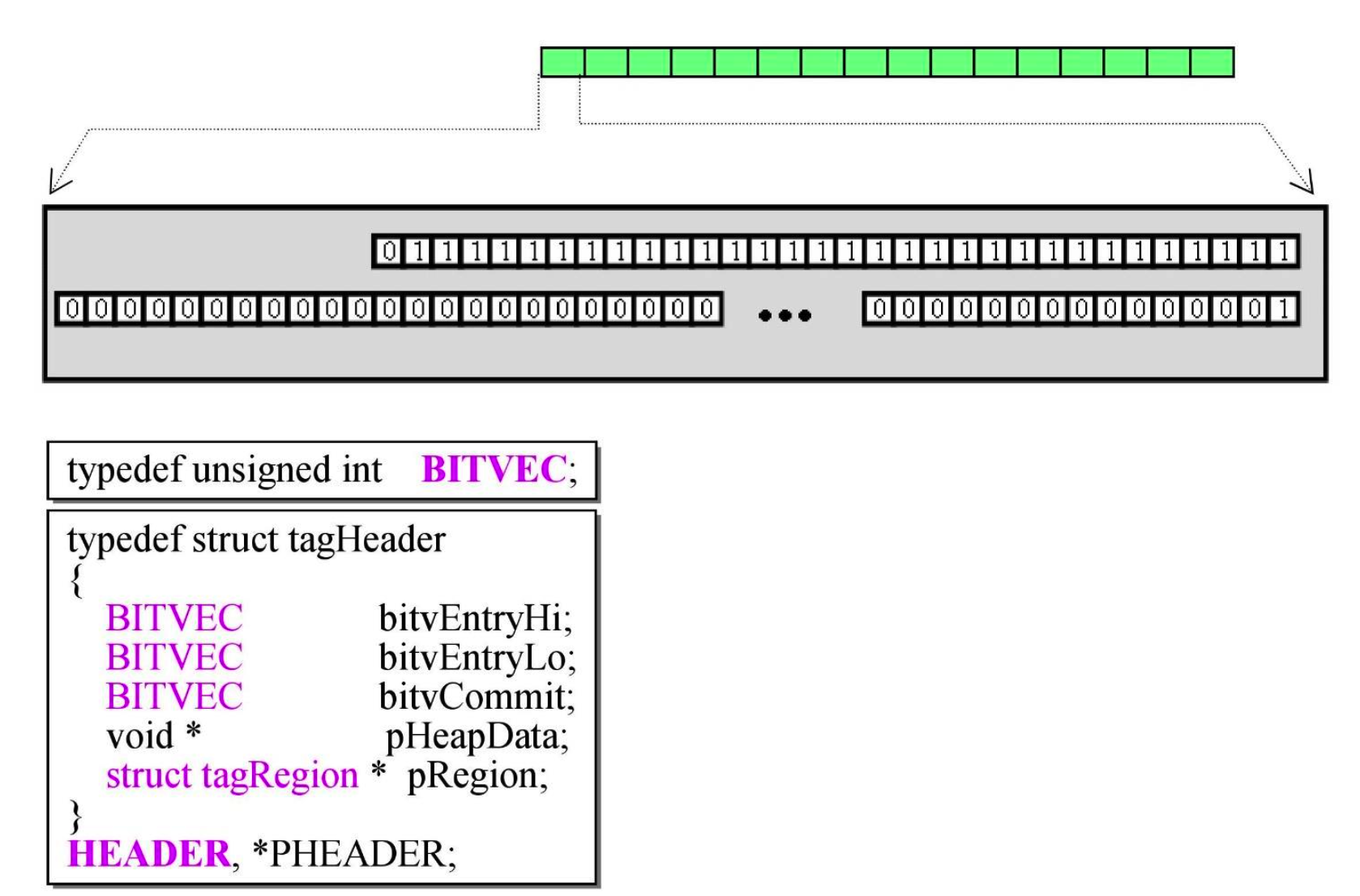
- 这就是 header
- BITVEC 就是 unsigned int,4字节
- pHeapData 指向真正的内存,pRegion 指向管理中心
# 3.3 VC6 内存分配

_ioinit()函数发出了第一次内存分配请求,所有程序的第一块肯定是它- 非 Debug 模式下 _malloc_crt 是 malloc,Debug 模式下 _malloc_crt 是 malloc_dbg,后者只是比前者多了一些东西,我们分析 Debug 模式
_ioinit()申请了 32 * 8 = 256 字节的内存(256 在 16 进制中是 100)

_heap_alloc_dbg()是在调整内存块大小,还没有分配空间- 传入的 nSize 变量就是刚刚的 256
- nNoMansLandSize 大小为 4
- _CrtMemBlockHeader 是 Debug 模式下会附加的内容,里面的 8 个数据与右侧图片对应。有时也会被我们称为是 Debug header
- pBlockHeaderNext 和 pBlockHeaderPrev 是指针,目前不涉及
- szFileName 和 nLine,记录是哪个文件的哪一行发出的申请,这里的例子中是 ioinit.c 文件的第 81h 行
- nDataSize 记录真正的大小
- nBlockUse 后面解释,2 代表是CRT_BLOCK
- IRequest 流水号码,现在是第一块,所以是 1
- gap[nNoMansLandSize] 4个字符,可以理解成和真实内容下面的部分共同形成“篱笆/边境”,帮助编辑器检查错误

- 这页依然是
_heap_alloc_dbg()函数,内容是调整指针 - 所有经过
malloc()分配的内存块统统都被它登记了起来,使用链表串连,即使这块内存已经给到用户了,仍然在 sbh 的掌控之下。这也就解释了为什么调试器可以实现追踪内存等功能。当然,前提是在调试模式下 memset()给特定位置设置特定的值:NoMansLand 填 0xFD,将来要回收的(DeadLand)填 0xDD,要清除的(CleanLand)填 0xCD。通过初值设定,调试器在未来可以检测这些内容是否被改变

_heap_alloc_base()- 用扩充后的大小(size)再次去与 __sbh_threshold(阈值)比较,<= 继续由 sbh 管理,超过大小就交给操作系统处理
- 为什么会是 1016 这么奇怪的数字?其实小区快的定义就是 1024(1k),因为 block 上下还要加 cookie(共 8 字节),所以要用 1016 去比较

_sbh_alloc_block()把之前得到的大小(intSize)加上 2*sizeof(int),其实就是加上两个 cookie- 下面的 +(BYTES_PER_PARA-1) 和 &~(BYTES_PER_PARA-1) 部分是 RoundUP,把加完 cookie 后的大小上调到 16 的倍数
- 可以说通过
malloc()分配的内存的实际大小,也是真正消耗掉的内存大小。过程是要分配的大小经过调整补充(4*8+4=36 字节,给调试器使用的)再加上 cookie(8 字节),最后调整为16的倍数。本例中,就是 256+36+8=300(0x12c),不是 16 的倍数,调整为 304(0x130)- 16 进制中,末尾为 0 的便是 16 的倍数
- 实际大小 0x130 会记录到 cookie 中,写成 0x131 表示这块内存已经给出去了,被 sbh 回收后会变成 0x130。使用最后一位标记也是因为 16 的倍数最后一位肯定是 0,所以可以拿来记录
- 虽然现在已经涉及到了这么多函数,但
_ioinit()->_malloc_dbg()->_nh_malloc_dbg()->_heap_alloc_dbg()->_heap_alloc_base()->__sbh_alloc_block()都是在计算内存的大小,还没真正进行内存分配,图中的那些值也都还没真正设置

__sbh_alloc_new_region(),才真正开始内存分配- 之前的 16 个 header,每个 header 都负责管理 1MB 的内存,为了对这块内存做管理,又建立了 region
- 图上橙色框的部分就是 region。bitvGroupHi 和 bitvGroupLo 合起来有 32 个组,每组 64 个 bit,用来管理哪些区块有或没有,在链表中存不存在这些小细节。grpHeadList 里有 32 个 group,每个 group 里有 64 条双向链表。region 中这些东西加起来大小约为 16k

__sbh_alloc_new_group(),从 header 管理的 1MB 中切出一块来- 32 个 group 对应 header 的 1MB,因此每个单元就是 1024/32=32k。这 32k 又分成 8 块,每块为 4k,计算机中通常将 4k 称为 1 个 page,所以下称 page。这 8 个 page 是连续的,sbh 会用指针把它们串起来,然后把它挂到 64 条链表的最后一条上
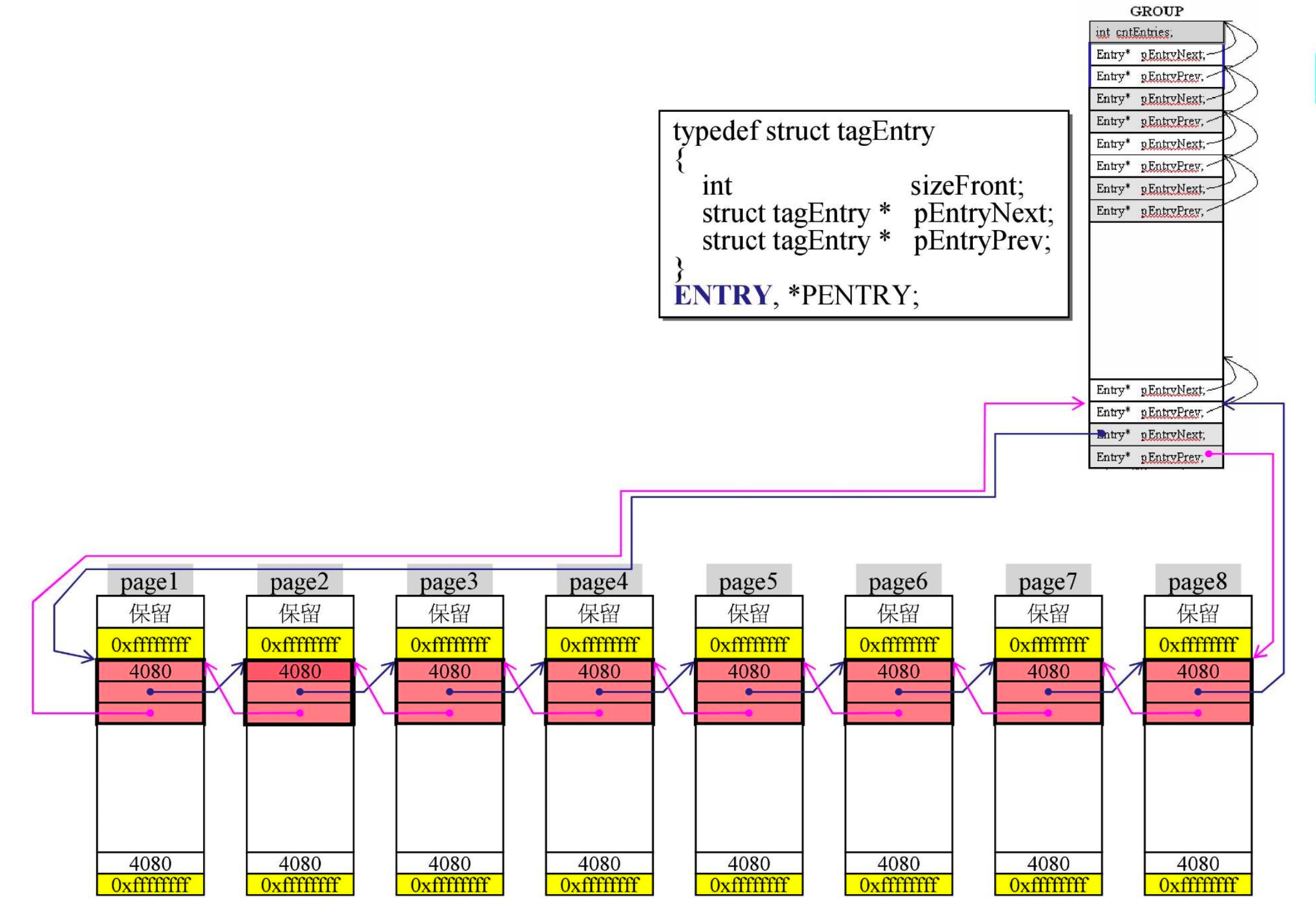
- 0xffffffff 是 -1,也是起到类似“篱笆”的作用
- 第一格记录的是这一块(两个黄色之间的部分)的大小,即 4080
- 总大小为 4096,两个黄色占 8,还剩 4088,但 block 要是 16 的倍数,所以取出 8 作为保留,以满足 8 的倍数(好听的说法是保留,难听的话其实就是浪费)。任何 block 都要带 cookie,记录自己多大,所以上下都记录了 4080
- 实现上的小细节:指针指回来会指到上一格(没有懂)
- 有点像 GCC 的分配器,64 条链表每条负责 16 的倍数内存大小,第一条负责 16 字节,第二条负责 32 字节,最后一条负责 1k。当切割的内存块大于 1k 的时候,也归最后一条链表管理。
- 这也解释了为什么所有 page 都串在最后一条链表上,因为每个 page 的大小为 4080,大于 1k,所以全部都归第 64 条链表管理

- 从 page 中切割内存块的操作
- 4080-304=3776(0xff0-0x130=0xec0),所以原先记录 ff0 的部分变成了 ec0
- 把红色的部分指针(007d0ed0)传出去,cookie 上的 130 也改成 131 后就算是完成了切割,一层层函数传回去后。最后
_ioinit()拿到的是绿色的部分,作为用户,它并不会知道上下有什么 - 这时,前两格(头尾指针)不应是 00000000 了,而是应该有值了,图片有误。nBlockUse 的 2 其实表示 CRT_BLOCK,这一块是给 CRT 用的,进入 main 之后分配的内存算是 NORMAL_BLOCK。这也意味着即使 main 结束后还有区块也不一定是内存泄漏,因为可能是 CRT 在用,如果 main 结束后还有 NORMAL_BLOCK 区块说明确实存在内存泄露
# 3.4 SBH 行为分析

- 用一张大图汇总上述的步骤
- 需求:ioinit.c 的 line#81(存疑,不应该是 16 进制的 81 吗)申请 100h,经过调整区块大小为 130h,由 #18 (304/16-1)链表负责提供
- 初始化的时候已经有 16 个 header,现在是第 0 个 header,先通过操作系统函数
VirtualAlloc(0, 1Mb, MEM_RESERVE,...)分配 1mb 的空间(从操作系统海量的内存中获得的空间)- 0:don’t care,从任意地方挖出 1mb 即可
- 1Mb:需要的大小
- MEM_RESERVE: 保留,保留这个地址空间,不需要真的有内存在这个地址,有点像只有门牌号但没有房子
- header 的另一个指针通过
HeapAlloc()从 _crtheap 中获取到一块大小为 sizeof(REGION) 的内存空间;REGION 中包含的东西在之前已经看过其结构体了,大小可以计算,其中还包含了 32 个 group,每个 group 包含 64 对指针 - 从 1mb 中通过
VirtualAlloc(addr, 32Kb, MEM_COMMIT)真正地划分出 32kb 的内存,将 32kb 再切成更小的单元,即 8 个 page,这 8 个 page 各有两个指针,通过指针将这些 page 串起来,最后串回到 64 个链表的最后一条- 在 addr 这个位置(就是红色格子的地方)给我 32Kb,MEM_COMMIT 代表真的要这块内存,沿用之前的比喻,不是只有门牌号了,而是真的有房子了
- 内存准备好了,下面开始切割
- 可以看出用户想要的实际空间上下都有 fdfdfdfd,如果用户在使用过程中有意或无意的改动了这部分,调试模式下调试器会检查这一块是否还是 fdfdfdfd,如果不是了,调试器会发出警告,说明存在隐患
- 130h 理应由 #18 链表供应,但现在只有 #63 链接着内存块,其他链表都是空的。这时 region 中的 64 bit 变量(对照图中表格,32 个 group 有 32 行,每行有 64 列,图中浅灰色格子是 char,和这 64 bit 无关)就派上用场了,64 个 bit 分别对应 64 条链表,0 代表链表为空,1 代表链表链接有区块。现在只有最后一个 bit 是 1。供应端可以把这样的情况告知用户。

- 另一个函数发起了需求
- 在添加 Debug header、cookie,调整为 16 的倍数后需要大小为 240h。应该由 #35 链表提供,但检查 group0 的 64 bit 变量之后发现只有最后一个 bit 是 1,其他都是 0,#35 为空,只能退而求其次,用更大的,是最后一条链表
- page1 中剩 0xec0,再切 0x240,还剩 0xc80
- group 结构体中的 cntEntries(图中链表最上面)是一个累积量,分配的时候 +1,释放的时候 -1。值为 0 时说明 8 个 page 都收回来了,可以还给操作系统
- region 结构体中的 indGroupUse(图中 region 左上角红色数字 0) 为索引,表示正在使用 Group0,如果 Group0 的所有 page 都用光了,就继续用 Group1、Group2……

- 第三次,再切 0x70,还剩 0xc10。流程和前面都一样

- 在第 15 次内存变化的时候观察到了内存释放动作(free 函数被调用)
- 累积量 -1,从 14 减到 13
- 释放的是第二次分配出的 240h,根据计算,应该归还到 #35 链表。回收的方式很简单,把 cookie 中的 241 改成 240 就算回收了(可能还会有相关数字修改的额外动作,不重要),原来被占用的空间也恢复成了两根指针,由 #35 链表回收
- 64 bit 变量中的对应位也修改,第 36(#35 是从 #0 开始算的)个 bit 修改为 1

- 需要 b0h,计算后由 #10 链表提供,#24 为 0,找更大的,发现 #35 有,于是从 #35 刚回收的 240h 中切
- 240h-b0h=190h,这个内存块变小了,需要移动,经过计算应该挂在 #24 上,第 25 个 bit 修改为 1

- 第 n 次分配的时候 Group0 只有三条链表挂有区块,而这次要 230h,比较大,这三条链表都无法满足它,于是新启动一个 group1,其他操作都一样

- 好的设计是,如果回收的内存相邻,就应该合并,不然整个系统会越来越碎
- 图中白色代表已经回收了的区块,阴影部分表示可以进行回收的区块
- 以图 1 为例,阴影部分的 301 应该和上下的 300 合并(合并不需要三块一样大,只是这里刚好都是 300),经计算,应该由 #47 链表管理,要归还阴影部分的时候,需要先把 cookie 的 1 改成 0,再判断上下是不是已回收(是不是白色)
- 延伸,直观来看 cookie 只需要一个用来记录就够了,为什么要上下两个一模一样的?因为没有下 cookie 就无法做到向上合并
- 图中弓箭的地方往上 4 个字节,知道了长度为 300h,于是从这个地址加上 300h 来到下一块内存的起点(即下一块的上cookie),检查最后一个 bit 是不是 0,发现是,于是合并为图2
- 因为上下都有 cookie,所以从弓箭处往上 4 字节,再往上 4 字节,就来到上一块内存的下 cookie,同样检查最后一个 bit,发现是 0,于是合并为图 3
- 然后计算 900h 应该挂到哪条链表上,并链过去

- 下面需要思考一个问题,16个 header 每个都有 32 个 group,32 个 group 则都有 64 条链表,如何确定
free(p)的 p 落到哪个 header 的哪个 group 的哪条链表 - 最开始有 16 个 header,__sbh_pHeaderList 指向这 16 个 header,每个 header 的大小是固定的。回收的时候知道内存块的大小,通过 p(指针地址)+内存块的大小,计算在哪个 header 的范围内即可
- 之后,用 p 减去这 1mb 的头部地址,再除以 32kb,即可知道落在第几段(group),如果从 0 开始,还需要 -1
- 接下来就是前面讲过的,通过 cookie 知道内存块大小,除以 10h 再 -1 ,确定落在哪条链表
# 3.5 VC6 内存管理总结
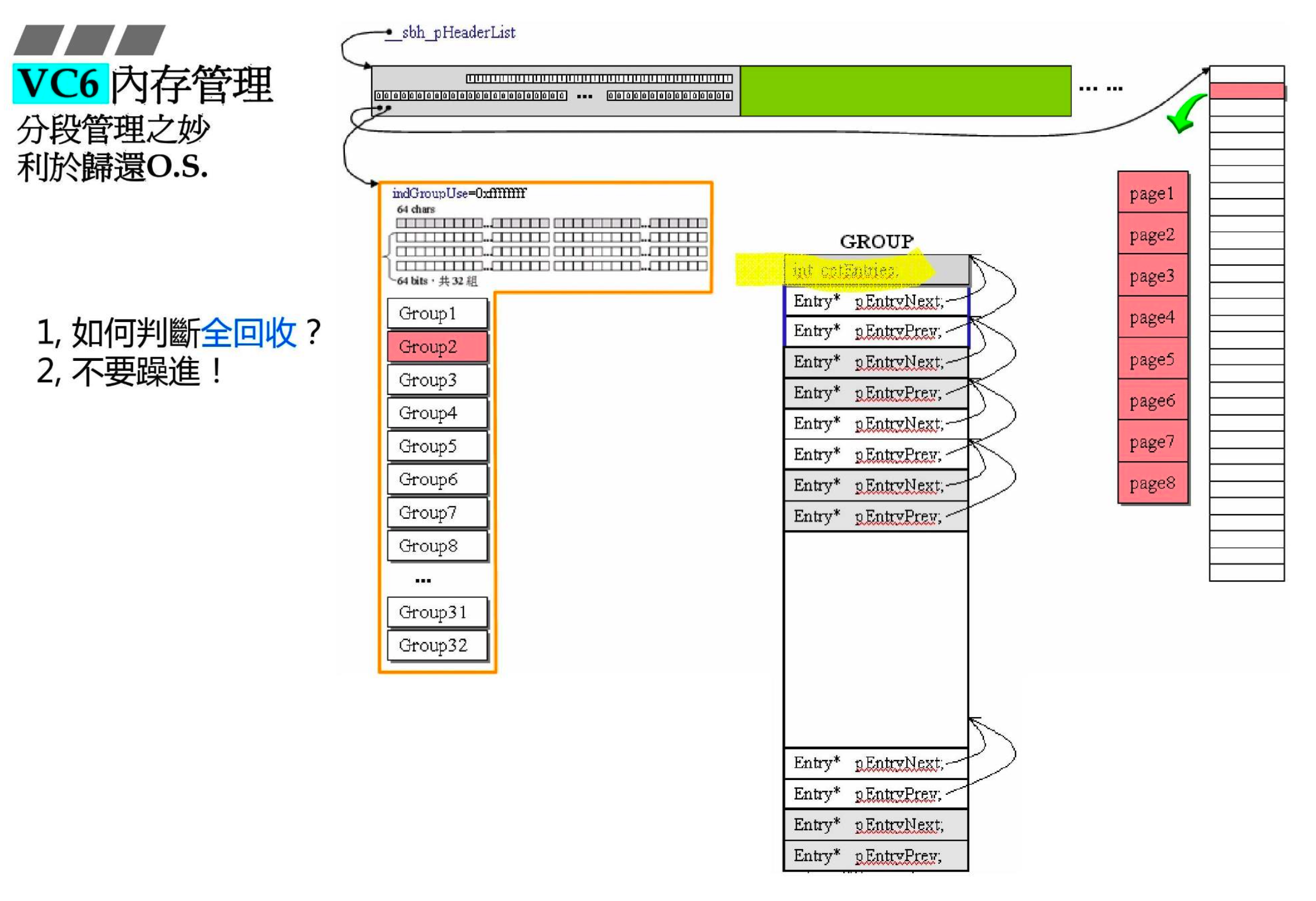
- 可以发现它是分段的管理,它其实可以直接找操作系统要海量的内存,但它真正只要了 32kb,为了实现这种管理才会分出这么多 header、group、链表
- 分段管理的好处在于可以更快地回收,1MB 四处分配之后再完全归还可能要天长地久,但一段 32kb 回收的可能性就大多了
- 如何判断全回收:cntEntries 变量为 0 时即可全回收
- 不要躁进:全回收之后就会回到初始的状态,8 个 page 就不会再合并了,因为它并不急着还给操作系统,比如第 10000 次全回收,第 10001 次又要内存,那整个就又要重来一次,所以它不着急,要保留到下一次全回收再还给操作系统

- 通过 defer 实现延缓全回收
- 手上已有一个全回收,并出现新的全回收时,才会把空间还给操作系统,并把第二个全回收设为 defer
- 手上已有一个全回收,如果客户又需要内存,它继续给出去,defer 设为 NULL
- __sbh_pHeaderDefer 是个指向 header 的指针,到底要全回收哪个 group 是由 __sbh_indGroupDefer 指向的

- 恢复到初始状态后是这样的,8 个 page 并不会合并

- VC6 在调试模式下提供多个函数供用户追踪链表等信息

- GCC 的 malloc 和 VC 差不多,我们就不一一介绍了
- 我们会发现 GCC allocator 和 malloc 是相似的,分配器做这些不是为了提高速度,malloc 已经够快了,目的是为了去除 cookie

- 可以发现从底层到顶层都有很多复杂的设计
- 浪费,但是有必要
- CRT(malloc/free)是 C 的层次,是跨平台的,不能预设下面的操作系统做了内存管理;同理,C++ Library(std::allocator)最重要调用 CRT,它也不能预设 malloc 做了内存管理,因为它是 C++ 标准库,不能依赖底层 C 的东西
- 前面说 VC10 已经没有 SBH 的管理,交给操作系统了,那是因为他确定运行在 Windows 下,可以放心依赖下面
# 4. loki::allocator
# 4.1 上中下三个classes分析
Loki Library 是一个在业界很前沿的库,但是不成熟,作者对这个库的维护只到0.1.7版本,上一次更新还是 2013 年。
之前讲过 GCC 的编译器不会将内存归还给操作系统,在多进程的时候会有影响。但是 Loki 会将内存进行归还。

- 使用者面对的是 SmallObjAllocator,下面两个是支撑它的
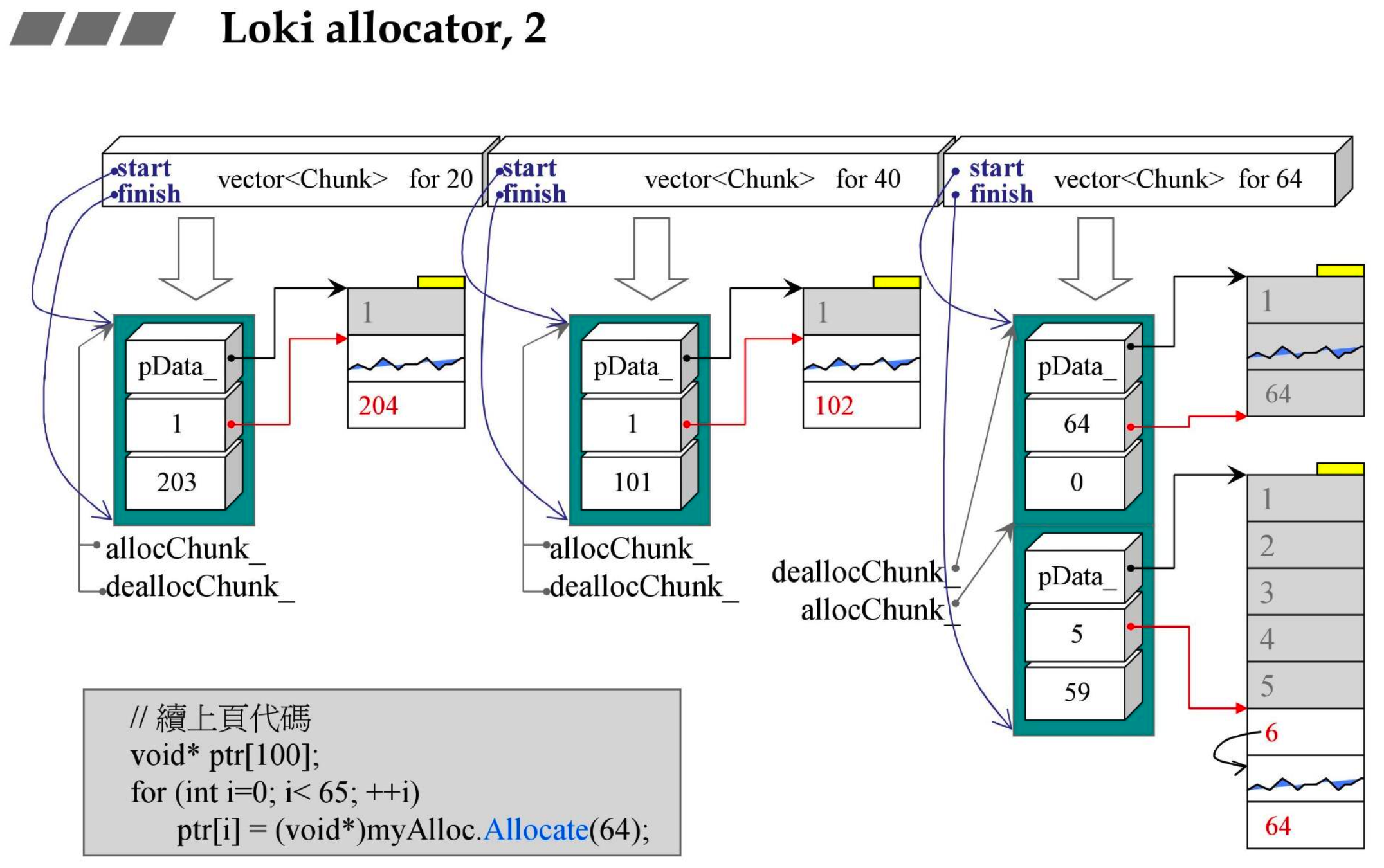
- Chunk
- pData_:指针,指向 unsigned char
- firstAvailableBlock_:第一个可用区块(接下来要供应的是第几号)
- blocksAvailable_:目前还可以供应几个区块
- FixedAllocator
- chunks_:放了许多 Chunk 的 vector
- allocChunk_ 和 deallocChunk_:指向 Chunk 的指针
- SmallObjAllocator
- pool_:放了许多 FixedAllocator 的 vector
- pLastAlloc 和 pLastDealloc:指向 FixedAllocator 的指针
# 4.2 行为图解





# 4.3 源码分析
# 4.3.1 Chunk
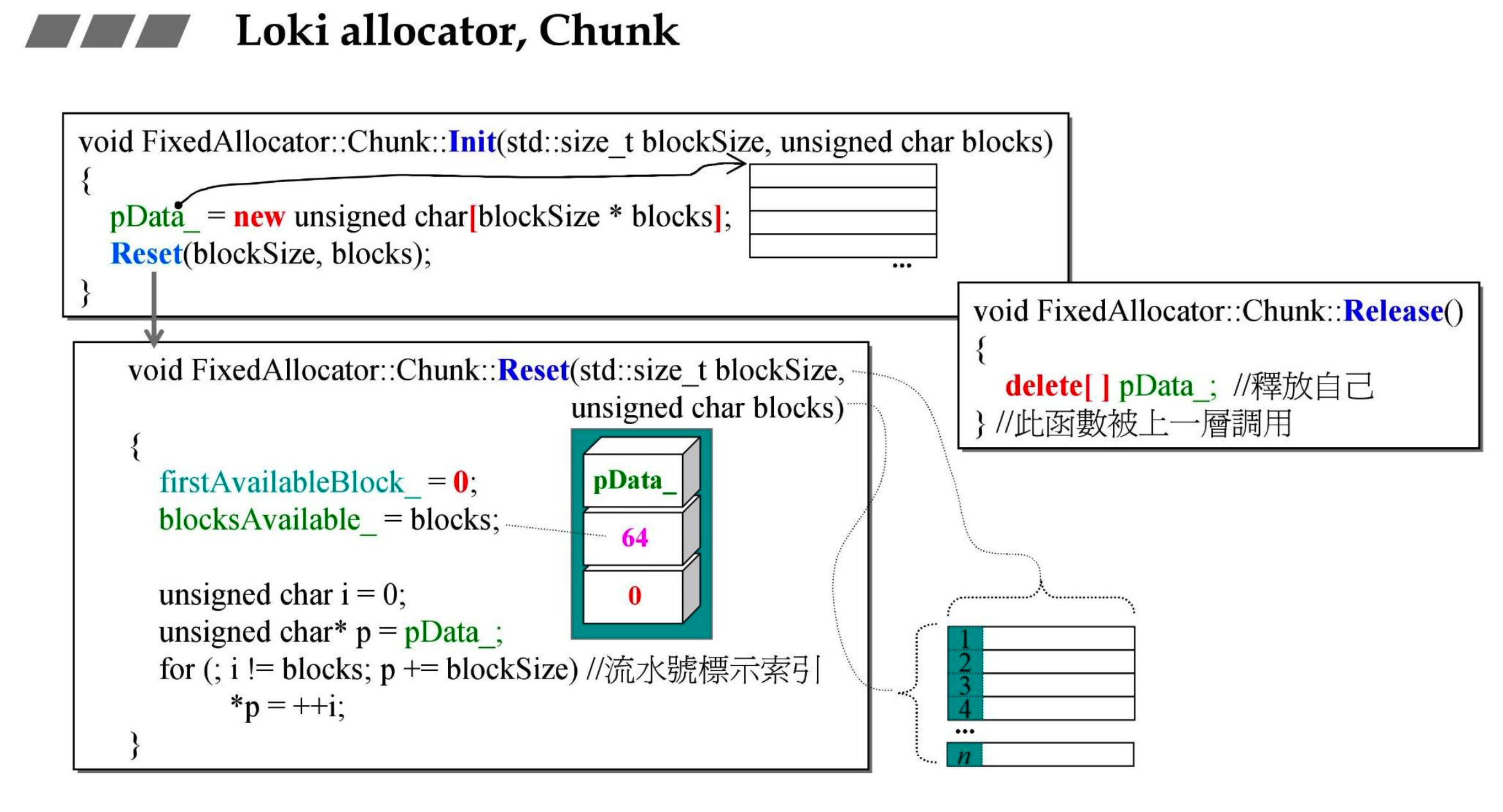
- 索引也是借用前面的位,有点像嵌入式指针

- 数组代替链表,索引代替指针

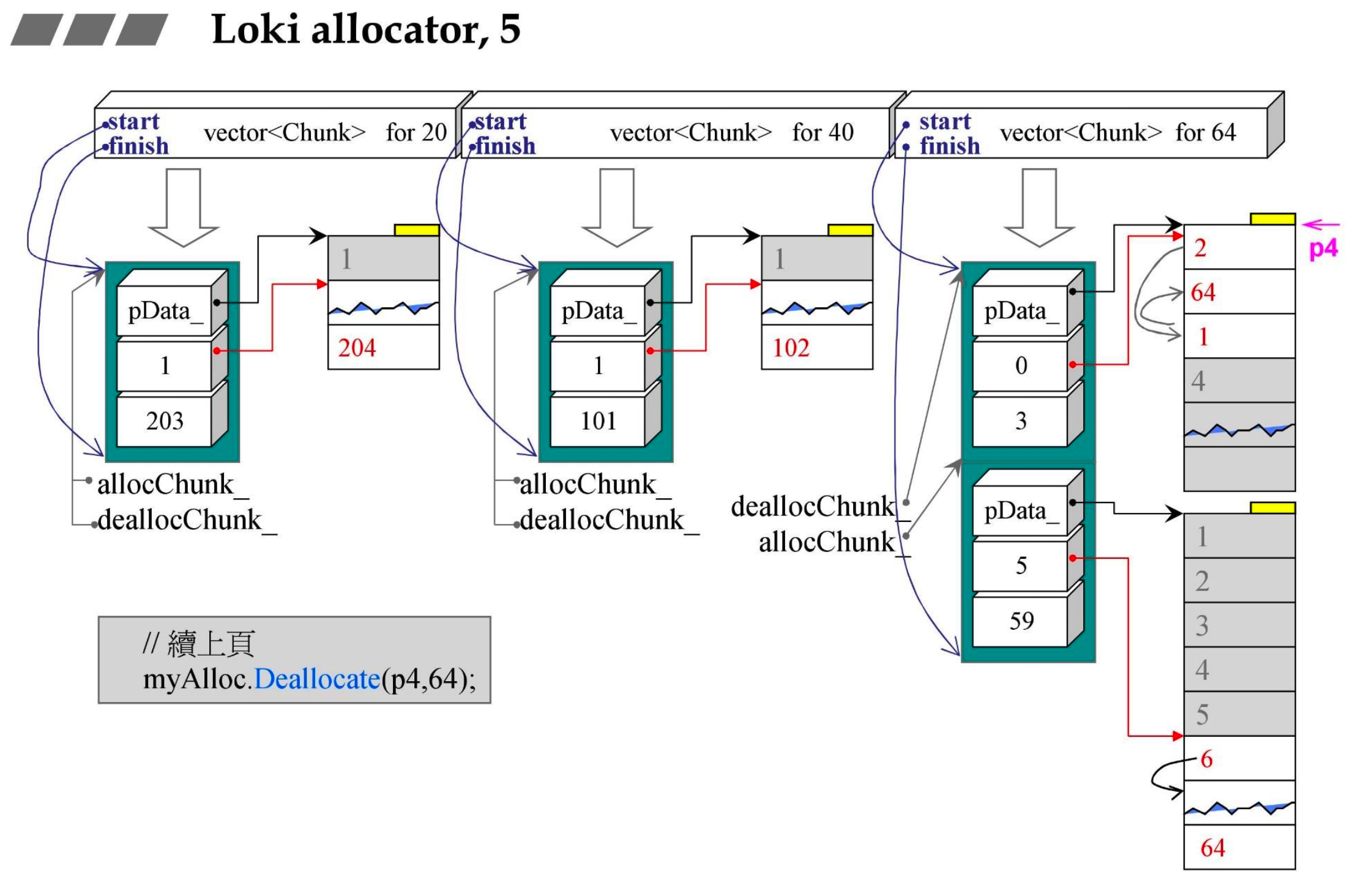
- 确定指针落在第几个 Chunk 第几块后,完成释放
- 第几块被释放,下一次分配时最优先分配的就是那块。就像链表中我们会把释放的空间放到链表头一样
- 现在的最高优先权是 3 号,回收 4 号后最高优先权变为 4 号,4 的下一个就应该是原本的最高优先权,所以 4 里填入 3
- 同时可用区块数 +1
# 4.3.2 FixedAllocator

allocChunk指针是用来标出最近的满足分配动作的 chunk,假设现在有一万个 chunk,第 327 chunk 上一次刚给出去,allocChunk就指向它,下一次再有分配的需求时,就从allocChunk指的区块先看deallocChunk同理,上一次回收的是第 n 号,这次回收我也从第 n 号开始确认- 这么做的逻辑是:计算机的数据有一种内聚性,先前还回来在这里,下一次还回来可能还落在这里
- 如果
allocChunk是 0(意味着初始状态),或指的那个块已经用光,就会从头找起,如果找到尾部都没有找到可用的,就新加一个 Chunk - #20 的
allocChunk = &*i;看起来是相互抵消了,但抵消只针对指针,而 i 不是指针,是迭代器,*i的意思是先取值,得到 Chunk,&*i就是再取地址,得到了 Chunk 的首地址 - 为什么新加 Chunk 的时候 #15 会有
deallocChunk = &chunks_.front():因为往 vector 中添加新的 Chunk 的时候可能会出现数据的移动(如果 vector 扩容的话),如果出现了数据移动,之前的迭代器都会失效,所以对这些值要进行重新设定 Deallocate()看起来代码很少,是因为把所有步骤都放到两个函数里了,第一步是先找上一次回收的是哪个,第二部是回收

- Vicinity 的意思是邻近
- lo 找不到就往上找,hi 找不到就往下找,这样上面找一个、下面找一个,不停找
- 如果 p 当初不是这个系统分出去的,就会找不到对应的 chunk,陷入死循环。新版加了一两行,解决了这个问题

- 回收之后会判断是不是全回收,也做了类似 defer 的处理
- 经证实,当前代码有 bug,有可能不会归还给操作系统,新版本也改好了
- SmallObjAllocator 只是找应该归哪个 FixedAllocator 负责,脱离了内存管理的主轴,所以我们不讲
# 4.3 检讨

- 很简单的方式:Chunk 记录可用区块还剩几个,当它恢复到原来的状态,就是可以回收了,和 malloc 很像
- loki 使用了 vector,它使用的 vector 的分配器是标准库的分配器,所以是两码事,并非鸡生蛋、蛋生鸡,但这也意味着你的代码里不但存在标准库的容器、分配器,也用到了 loki 的分配器。更好的做法是不在 loki 里使用 vector,改用自己写的容器
# 5.Others
# 5.1 GNU C++ 对 allocators 的描述

- n 指的是元素个数而不是空间总量(字节)。注意,GCC2.9 的那个分配器是字节,但不算标准规格。
- 就是因为何时调用和多么频繁调用都不清楚,所以我们要自己设计内存池

__gnu_cxx::new_allocator和__gnu_cxx::malloc_allocator没有什么特殊的设计,没有内存池的设计,这就是最容易满足需求的做法__gnu_cxx::new_allocator相对来说稍微好一些,因为::operator new可重载。

- 所谓智能型,也就是内存池
fixed-size pooling cache固定大小的内存池缓存,就是第二讲中提到的 16 条链表,每条管理不同大小的内存块,内存块都是 8 的倍数- bitmap index 更复杂一些,后面会详解
- cache 就是之前提到的先准备一大块内存,然后慢慢划分,最大的优势是去除 cookie,同时因为减少了malloc 的调用,速度上有一些提升,但这不应该是最大的优势
__gnu_cxx::__mt_alloc是多线程的 allocator

- 分配器都有一个父类,所有分配和归还都交给父类去做,用户面对的都是子类
- high-speed 只是叫法,并不是说多高速
- GNU C++ 提供三项综合测试

__gnu_cxx::debug_allocator,说实话,没什么用- std:array objects 实际上是数组。因为数组是静态的,所以不会在“运行期添乱、增加开销”
- "甚至在 program startup 情况下也可使用"的意思是在进入程序员编写的程序 main 之前就可以使用
__gun_cxx::array_allocator了,也就是说还没有准备好动态分配的时候,就已经有__gun_cxx::array_allocator了。不过在 VC6 下的 startup 被写成了一个函数mainCRTStartup(),这个函数里的第一个动作就是_heap_init()进行内存管理的初始化,除非是在这个动作之前还要做事情,否则"设置在program startup 情况下也可使用"这句话的意义就不大了,因为内存管理的初始化完成后,其他的分配器也可以使用了。其实也没什么用
# 5.2 new_allocator 与 malloc_allocator

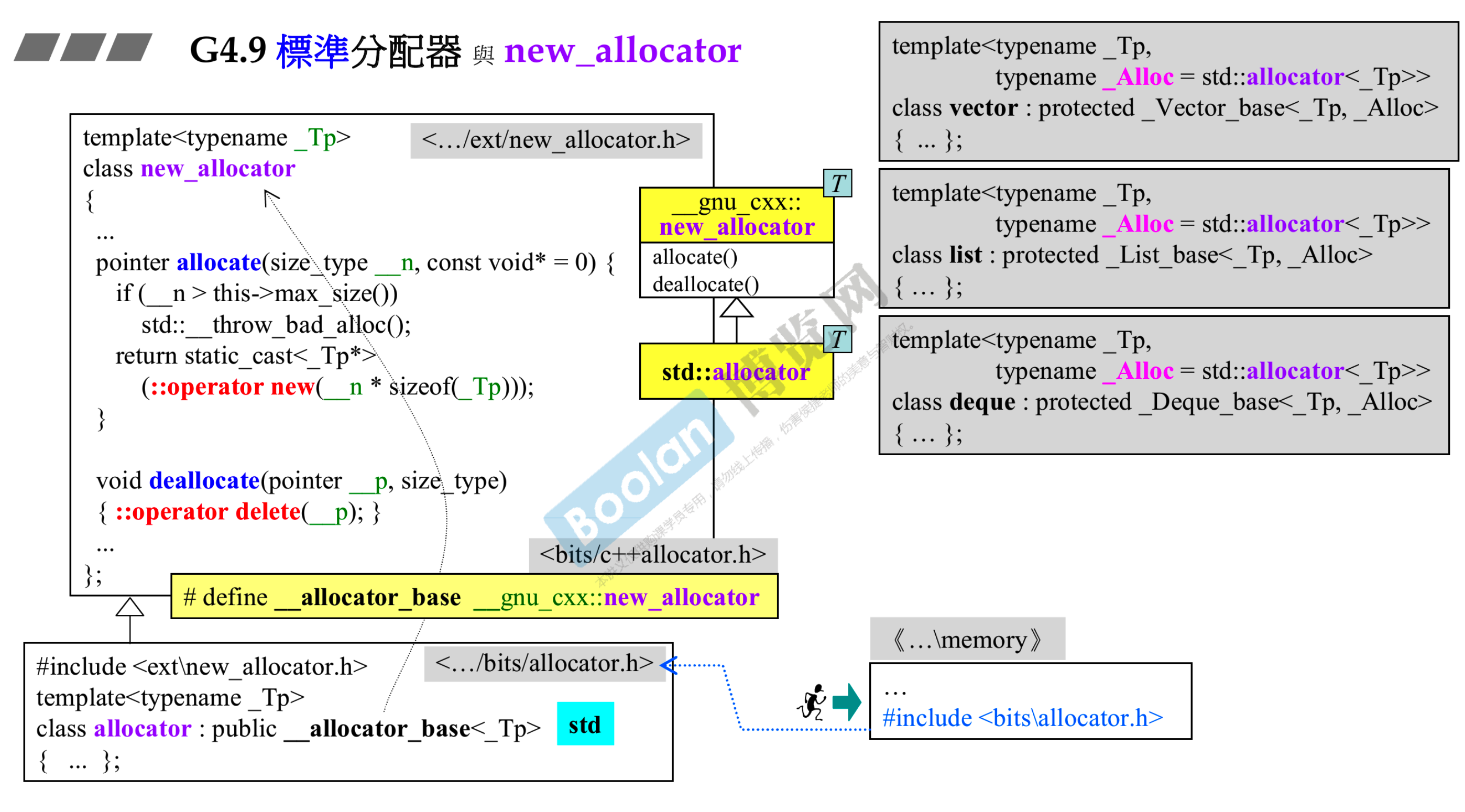

- 都没做什么额外操作
# 5.5 array_allocator 与 debug_allocator

- 第二模板参数不管是使用
std::tr1::array还是std::array都一样,因为本质相同,底部是一个C++的数组 - 由于数组是静态的,无需释放,所以
array_allocator里面只有allocate()函数,如果调用deallocate()则是会调用到父类的接口,但是这个接口里面什么都没做,是空的
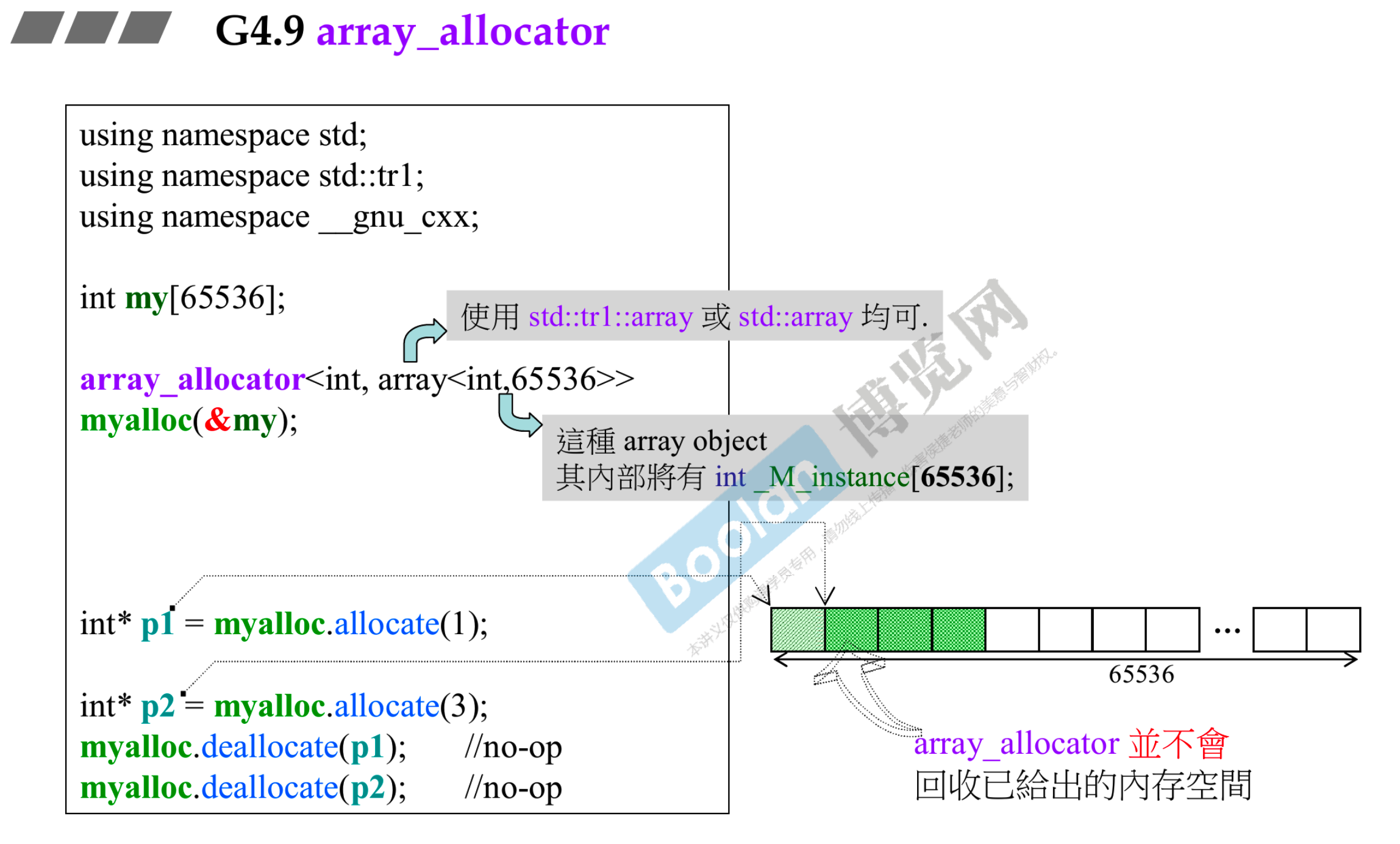
- 65536 是例子中随意取的大小

- 上一页是静态数组,这一页也是静态数组,但是用动态分配(array obj)的方式完成

- M_extra 是额外空间,它的大小是算出来的。
sizeof(size_type)在绝大多数系统中都是 4 字节,记录区块的大小。_S_extra()的计算结果表示额外的内存相当于占用几个元素 - 给到用户的指针是白色块前面的红箭头
- 包裹另一个分配器,让分配的区块多带 extra 的空间,用于记录整个区块的大小,扮演的角色类似于 cookie。内存池本来就是为了去 cookie 的,去除 cookie 之后再调用 debug_allocator 包一层,实在没什么意义
# 5.6 __pool_alloc

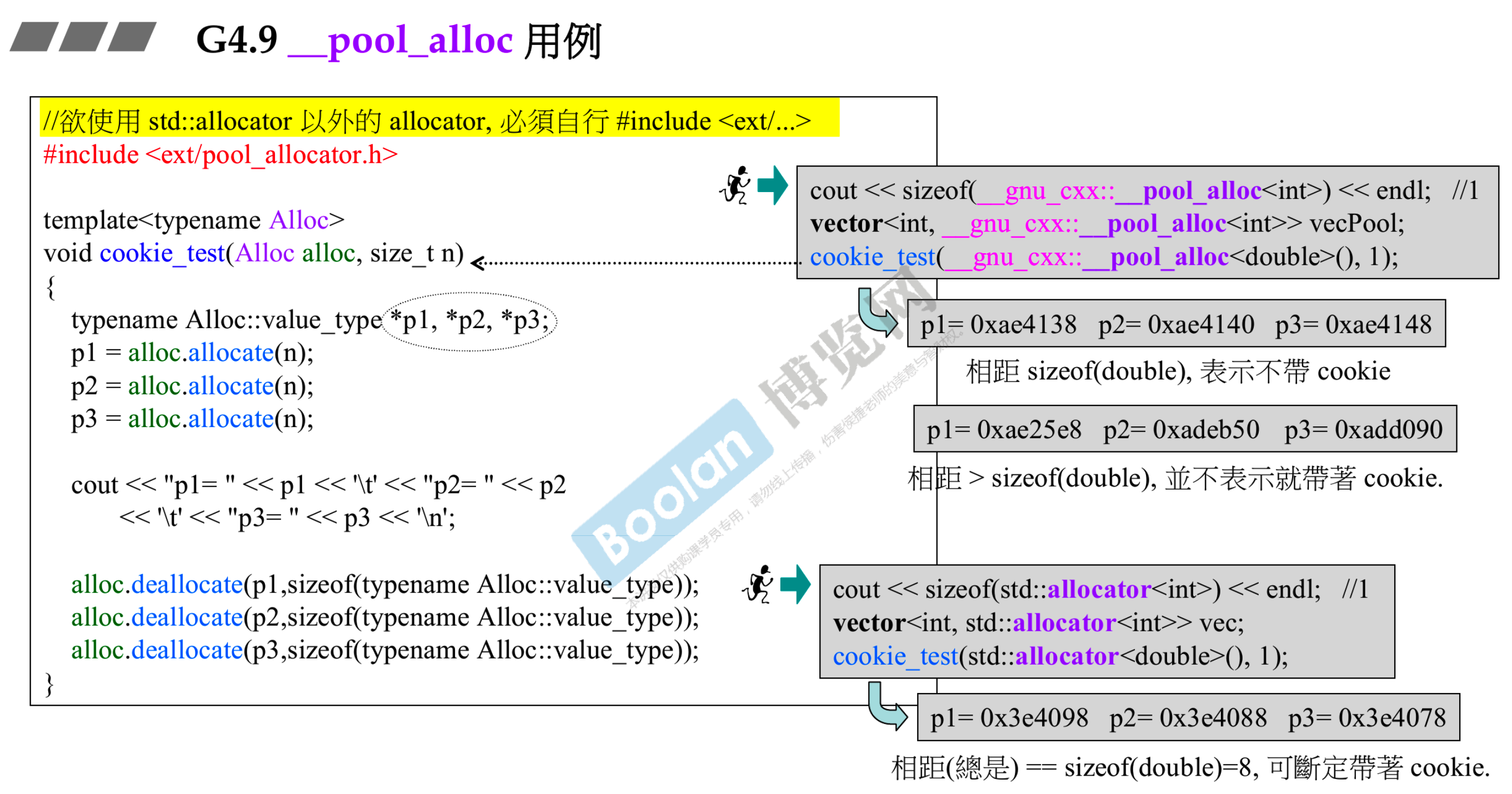
- 第二讲已经仔细分析过了
- 只拿不还,不会影响自己,但可能影响电脑上的其他进程
- 真正有用的分配器是这种智能型的分配器,我们追求的是没有 cookie
# 5.7 bitmap_allocator

- 重点不是源代码,而是行为模式
- 最重要的动作
M_allocate_single_object(),每次只供应一个,一个以上的话就直接operator new()了。其实很合理,因为分配器都是给容器用的,而容器一次都是要一个元素,很难想象什么情况下不是一个
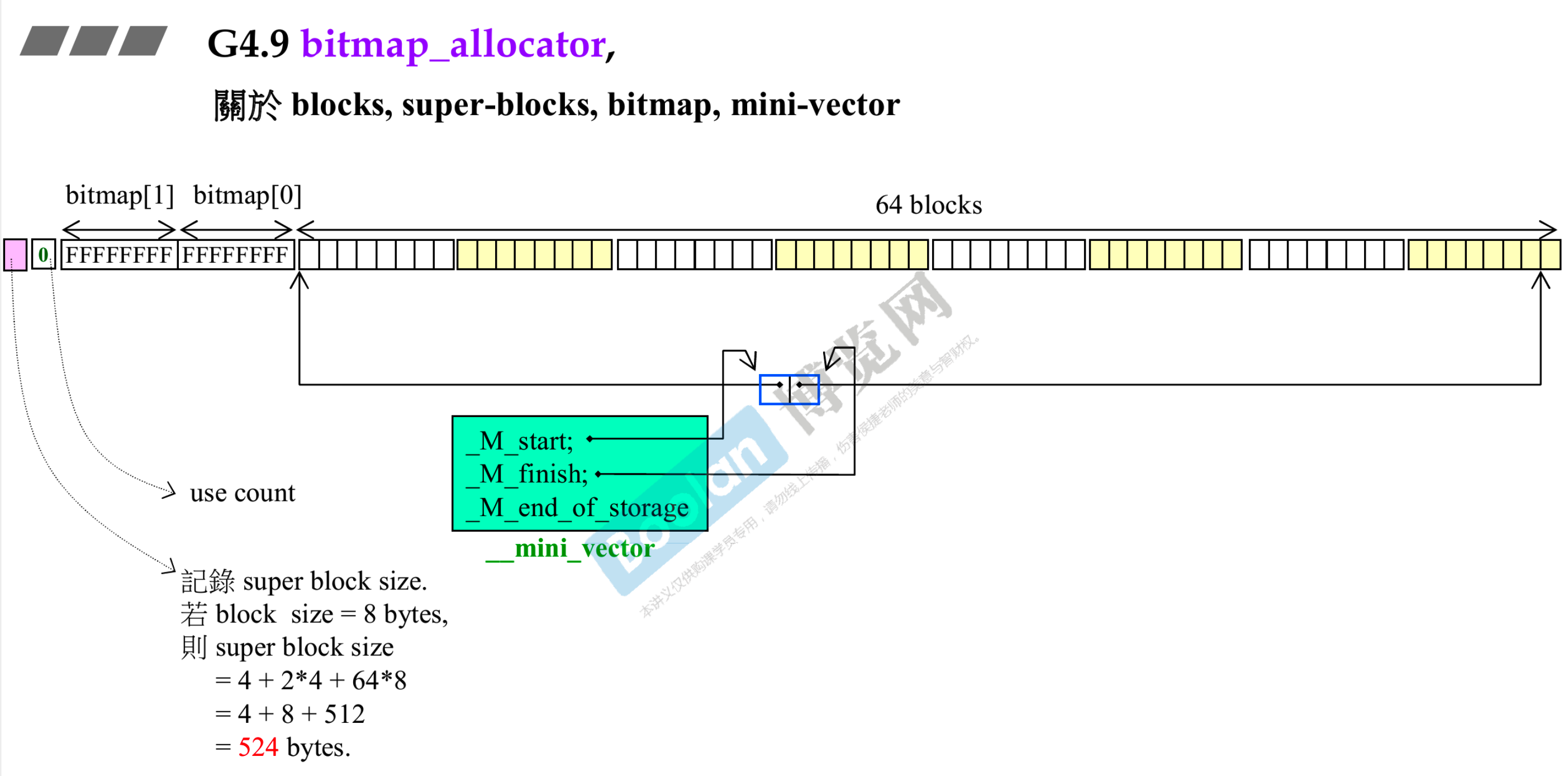
- blocks:用户要的,这里的一格。一次性会申请 64 个 blocks 用来做后续供应,未来两倍增长
- super blocks:包括 blocks+bitmap+use count
- bitmap:里面有 64 个 bit,用 0 1 记录在手中还是给出去了,它使用的单元是 unsigned int,每个是 32 位,所以 64 个要用两个 unsigned int
- use count :当前使用了几个 block
- 前面的粉红色记录了 super blocks 的大小,计算出来现在是 524 字节
- __mini_vector:操纵 super blocks,两个指针分别指向 blocks 的第一个和最后一个元素后面。每个 super blocks 对应一个 __mini_vector。其实是作者自己实现的 vector
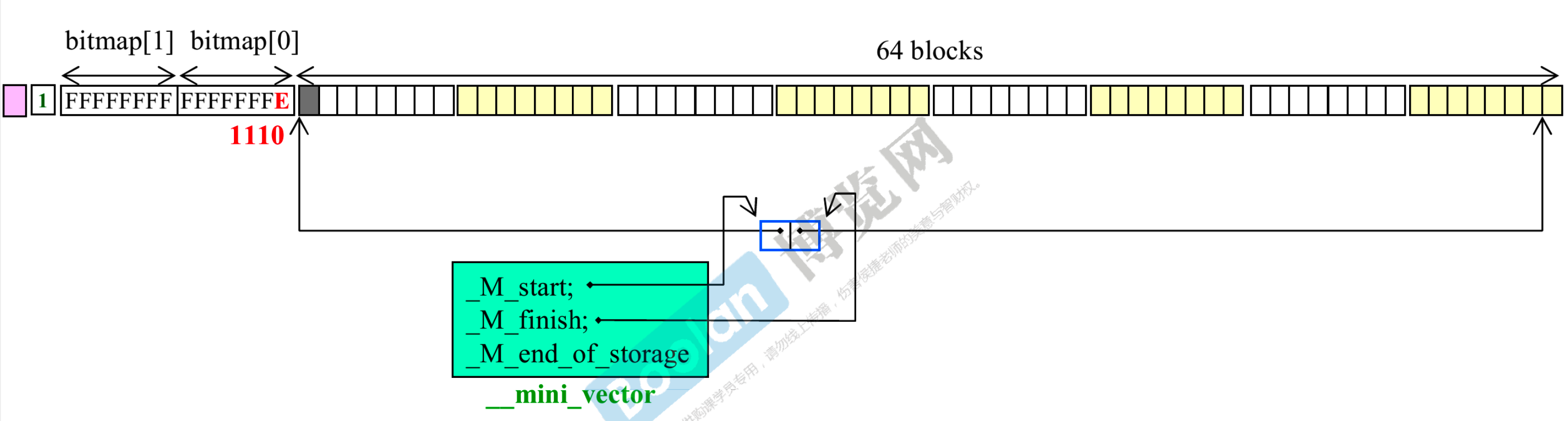
- 分配了第 1 个block
- use count 加 1
- bitmap 的变化次序和 blocks 的变化次序相反,blocks 从左往右,bitmap 从右往左。bitmap 的最后一个 bit 变成 0
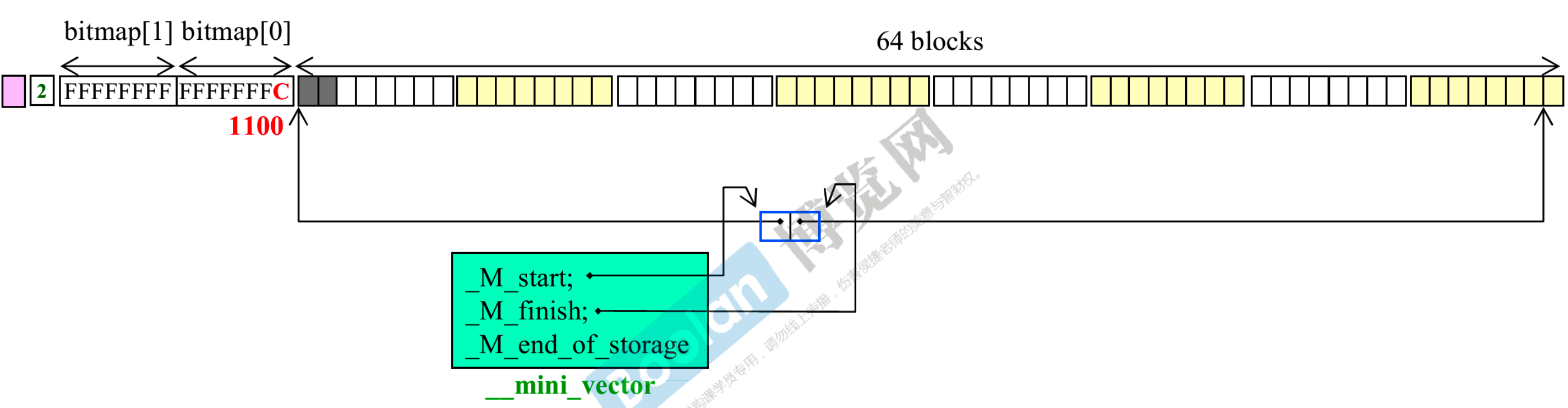
- 分配了第 2 个 block
- use count 加 1,变成 2
- bitmap 的倒数第二个 bit 变成 0
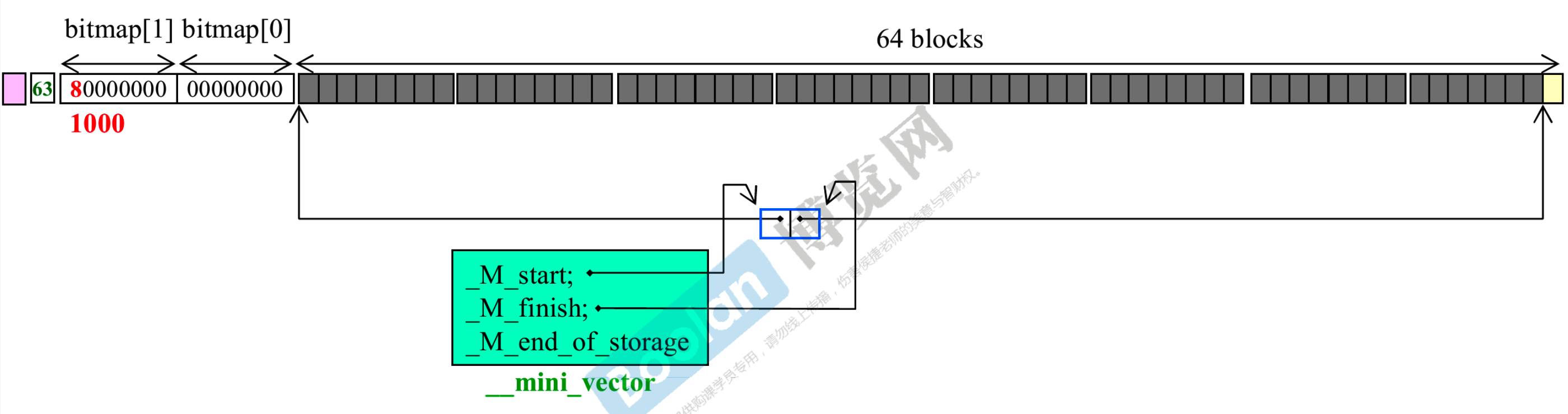
- 已经分配了 63 个 blocks
- 只有最后一个 block 没有使用,所以对应 bitmap 的第一位为 1,其他都为 0

- 将倒数第三个 block 归还
- use count 变成 62
- 相对应的 bitmap 变成 1010

- 第一个 super block 用光了,启动第二个 super block
- 第二个 super block 有 128 个 blocks,bitmap 也要有 4 个整数
- __mini_vector 也多了一个单元。因为 __mini_vector 是仿照 vector 写的,在增长时其实出现了数据的搬动(小细节)
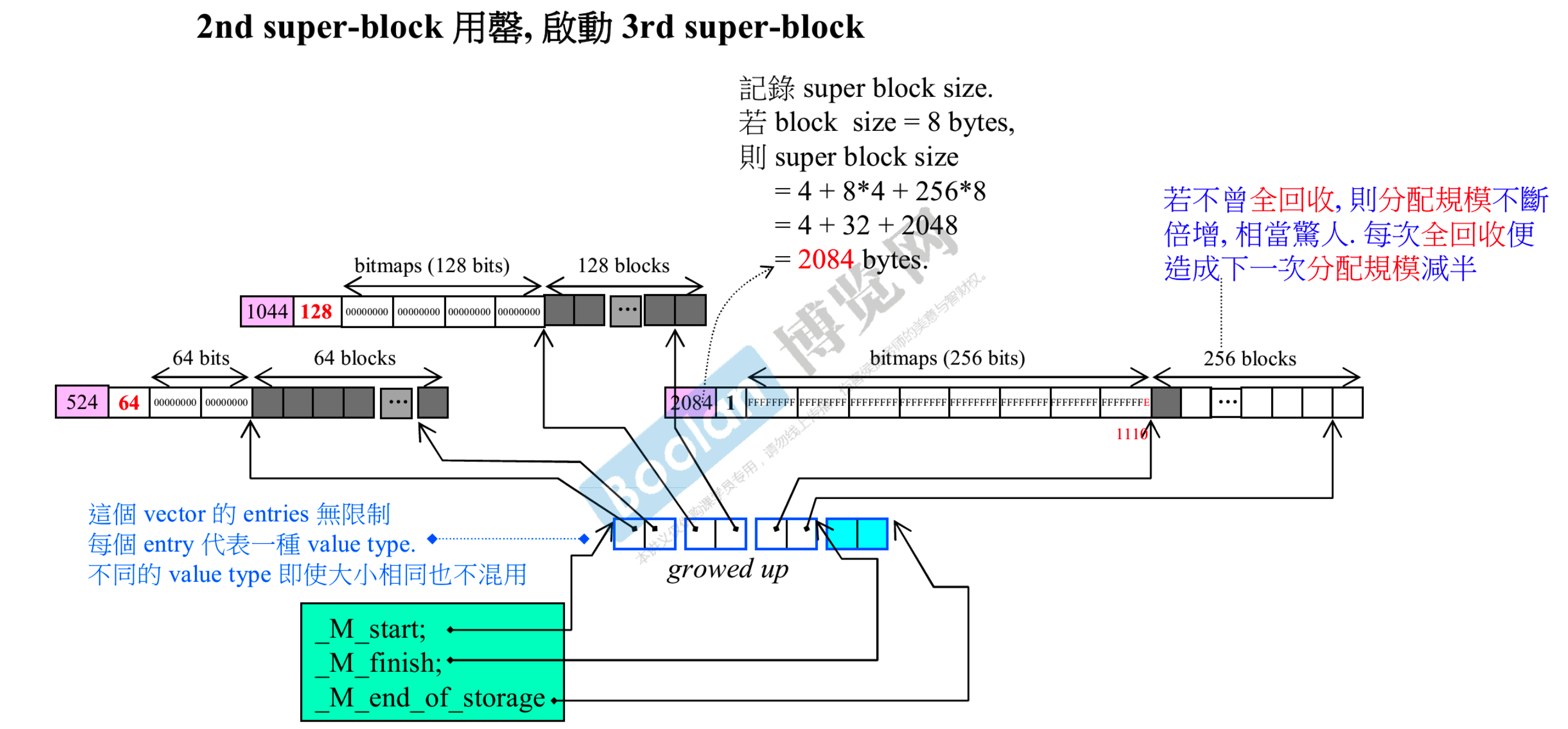
- 第二个 super block 用光了,启动第三个 super block
- 第三个 super block 有 256 个 blocks,bitmap 也要有 8 个整数
- __mini_vector 也多了一个单元。__mini_vector 是二倍增长的,所以此时其实有 4 个单元,只是最后一个单元还尚未使用
- 如果不层全回收的话,分配规模会增长的非常快
- 不同的 value type 即使大小相同也不混用,每个 super block 只为一种 value type 服务

- 第一个 super block 的元素都还回来了,bitmap 全是 F,use count 也变为 0,于是全回收,用另一个 __mini_vector(只有一个指针,逻辑名字为 free list)链上。这个 __mini_vector 最多放 64 个,第 65 个就要还给操作系统了
- erase 的操作就是把这个元素去掉,然后后面的都往前推
- 两个 QA 是观察后得出的结论。1st super block 就是 #0

- 步骤相同
- free list 会按 super block 的大小排序。如果 free list 已经有 64 个了,新进入的比最后一个还大,就直接 delete 新进入的,否则 delete 最后一个,把新进入的放到适合的位置

- 虽然都回收了,但 __mini_vector 也不会变小,还是 4
- 如果现在需要 1 block,就不再申请第四个了,而是把之前回收的三个的其中一个拿回来
# 5.8 用法
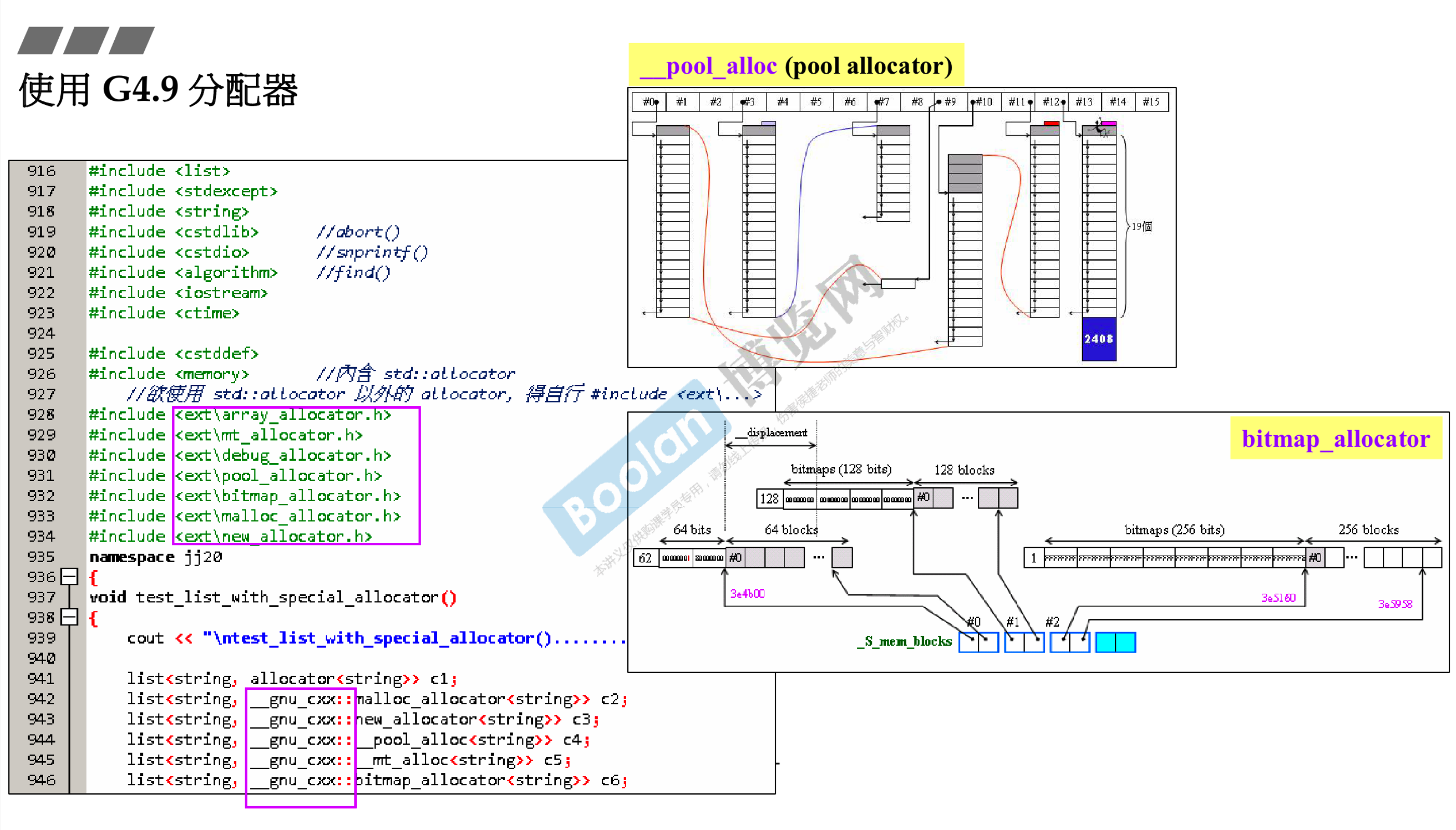

- 测试程序,使用时应该如何填写模板参数
后面还有 const、动态分配与 new、delete,在《侯捷 C++ 面向对象高级编程(下)》中已经讲过了