# 1.STL 体系结构基础介绍
# 1.1 认识 headers、版本、重要资源
- Generic Programming(GP,泛型编程),使用template模板为主要工具来编写程序。
- STL 是泛型编程最成功的作品。

- C++标准库(C++ Standard Library);C++标准库 .h 文件编译器自带,可以看到源代码
- 可以认为标准库中 70% 都是 STL,二者是包含关系
- 新式 include C header 的写法是把 .h 去掉,开头加上 c,如
#include<stdio.h>写成#include<cstdio> - 新式头文件都封装在 std 名称空间中,
using namespace std;
# 1.2 STL 体系结构基础介绍
# 
- STL六大部件
- 容器(Container)
- 分配器(Allocators)
- 算法(Algorithms)
- 迭代器(Iterators)
- 适配器(Adapters)
- 仿函数(Functors)
- 容器帮我们把内存的事情都解决掉,所以背后要有分配器来支持;有一些操作是容器里面做的,还有更多东西独立出来,成为算法;算法为了处理容器里的内容,需要有访问的方式,这个桥梁就是迭代器(可以认为是泛化的指针);仿函数的作用像是函数;适配器可以帮我们做一些转换,容器、仿函数、迭代器都可以做转换

- 其实大部分人都可以不用操心分配器,因为容器的源码里默认参数会指明分配器,这里为了教学才写出来
count_if算法帮我们计算符合条件的元素有几个,这里是计算大于等于 40 的元素有几个;为了告诉它元素的范围,我们用迭代器给它头和尾;我们找到了仿函数less,并用适配器bind2nd将第二参数绑定为 40;not1适配器是反义,会判断是否大于等于 40,返回 true false。- 最后代码输出为 4

- 标准库采用前闭后开区间
begin()要指向第一个元素,end()不是指向最后一个元素,而是指向最后一个元素的下一个位置- 因为迭代器是泛化的指针,所以指针能做的迭代器都能做,ite 可以
++``--``*``->,上面的例子是习惯的遍历写法

- 现在更推荐这种新写法(range-based for statement)
# 2.容器分类与各种测试
# 2.1 结构与分类
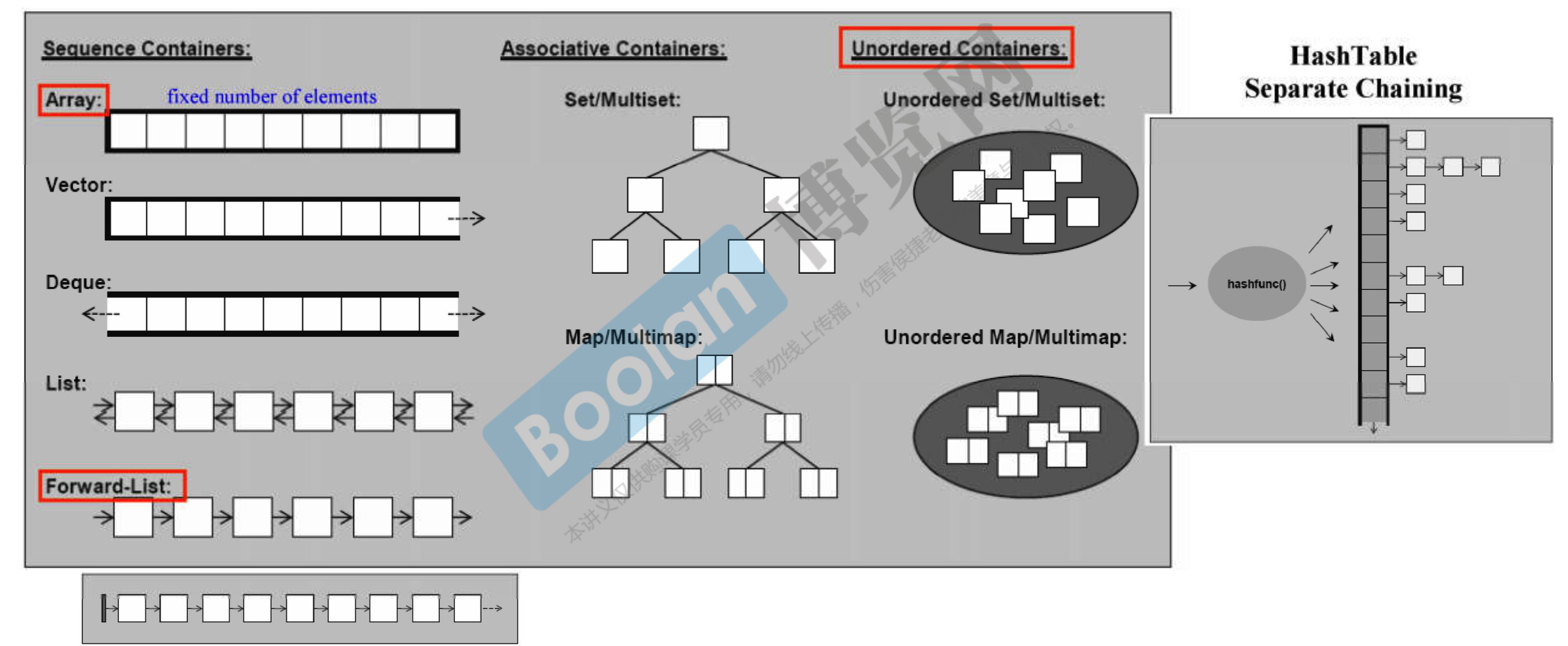
- 容器分为序列式容器(Sequence Containers)、关联式容器(Associative Containers)。无序容器(Unordered Containers)其实也算是关联式容器
- 红色框代表是 C++11 新增的
- 序列式容器
- Array 是把语言中的数组包装为 class
- Vector 在空间不够时会自动扩充
- Deque 双向队列,前后都可扩充
- List 链表,每个元素用双向指针连接
- Forward-List 单向链表,比 List 更省内存(少一个指针就省 4 个字节)
- 关联式容器
- 能够高速查找,底层用红黑树实现(一种自平衡二叉查找树)
- Set 不分 key 和 value,Map 的每一个节点有 key 和 value
- Set 和 Map 的 key 都不能重复,但 Multiset 和 Multimap 可以
- 无序容器的底层实现是 HashTable,标准库的实现方式是 Separate Chaining(分离链接法),将具有同一个 hash 值的 key 存到一个链表中,解决碰撞(冲突)

- 以下是后面测试程序会用到的辅助函数
get_a_target_long()用交互方式让使用者输入要查找的元素;get_a_target_string()把输入的数字转成字符串,为了体现实际使用中容器不会只存储数值;compareLongs()和compareStrings()比较 long 或字符串的大小,未来传给 qsort 快速排序函数使用。
# 2.2 序列式容器
# 2.2.1 array

- ASIZE 告诉 array 数组长度为五十万(这个参数不能省略)
array.data()会返回这个数组在内存中的起点地址qsort()的四个参数:起点地址、多少个元素、每个元素大小、怎么比大小- 使用二分查找之前一定要先排序
# 2.2.2 vector

- 插入一百万个数据
- 只有
push_back(),插入到数据尾部,因为只能往后扩展。每次push_back申请的空间以两倍增长,会申请预留空间;size 是大小,capacity 是申请的内存空间大小(两倍增长那个)。 - try 和 catch 捕获异常,以防输入测试数量过大,内存空间不足

- 找 23456 没什么特殊意义,随便打的数
find()是标准库的算法,模板函数,按顺序查找。不加::编译器也会自动从全局找,写上是为了更清晰sort()是 C++ 标准库提供的,bsearch()是 C 库里的
# 2.2.3 list

- list 每次
push_back只需在空间中找一个节点大小- 相比之下 vector 每次扩充不光要先开出两倍的空间,还要把之前的数据都移到新的空间,步骤更多
- list 有
max_size(), forward_list 和 deque 也有。为什么会有 max_size()?后面我们再看 - 这里使用的不是全局的
sort(),而是 list 容器自己的sort()当容器自己提供sort()的时候,建议使用自带的
# 2.2.4 forward_list

- 没有
push_back(),只有push_front(),因为是单向的,只能在头部插入元素 - 在 C++11 之前还有
slist,不在标准规范中,用法等完全相同
# 2.2.5 deque

- 这张图详细描述了它的结构
- 可以发现 deque 是分成一段一段的,每段内部是连续的,即分段连续,使用者感觉起来会是连续的
- 空间用完时,每次会扩充一个 buffer,相比之下 vector 的扩充可能会有很大的浪费

# 2.2.6 stack

- deque 涵盖 stack 和 queue,源代码也是如此,stack 和 queue 内部其实都是用 deque 实现的
- 因为这两个容器没有自己的数据结构,所以很多人在技术上不认为这两个是容器,而是将它们称为容器适配器
- stack 先进后出,queue 先进先出
- 不提供 iterator,因为可能会破坏先进先出或先进后出的机制,所以这里没有示范
find()
# 2.3 关联式容器
# 2.3.1 multiset

- 因为一百万次极大概率会出现重复数据,所以测试 multiset
- 数据并不是插入到头或尾,而是根据一定规则插入(自动排序),不需要用户操心
- 自己的
find()比全局find()快很多,是 0,可见关联式容器查找速度很快,相应地在数据插入时会慢一些
# 2.3.2 multimap

insert()时要自己用 pair 把 key 和 value 组合起来- 用容器自己的
find(),同样很快
# 2.3.3 unordered_multiset

bucker_count()桶的数量,桶的数量一定比现有元素数量还多,因为每个桶出去的链表不能太长,如果元素数量 >= 桶的数量,桶的数量就会扩充到原来的两倍(原有元素也会重新打散分配)

- 同样的,自己的
find()很快
# 2.3.4 unordered_multimap

- 没什么好说的
# 2.3.5 set

- key 不可以重复,真正放进去的数据不会有一百万个,图中显示,只有 32768(随机数产生刚好是 0~32767)
# 2.3.6 map

- multimap 不可以用
[]做插入,但 map 可以:c[i]=string(buf);,i 和 map 会自动合成 pair - map 真正放进去的数据依然有一百万个,因为 key 其实没有重复,只有 value 重复了
# 2.3.7 unordered_set 和 unordered_map


- 底层为哈希表,没有什么可说的
# 2.4 其他补充
- 还有叫作 priority_queue 和 heap 的容器,一个是用的比较少,二是底层实现为其他容器,所以这里不做测试
- 早期有 hash_set、hash_map、hash_multiset、hash_multimap,(现在改名为 unordered_... 后加入到标准库了)就像 slist 一样,如果你想让使用它们的旧程序依然可以正常编译,需要在导入头文件时加上 ext,如
#include <ext\slist>
# 3.分配器测试

- 不同编译器的分配器设计可能有所不同
- 每个容器类都有默认的容器分配器(红色部分)

- 以上是 gcc 编译器的测试代码
- 测试中选择 list 作为容器,搭配不同的分配器,这些分配器定义在
__gnu:cxx命名空间下

- 可以自行调用
allocate()和deallocate(),但没有必要。尽量使用容器,容器之外小量内存申请就用 new、delete 或 malloc、free;不需要记住当时申请内存的大小,这才是对的、好的。直接用分配器在释放(deallocate())的时候不仅需要指针,还要指明申请时的大小,记忆负担重,并不好用
# 4.源码分布及技术基础
# 4.1 源码分布

- vc 很直白,gcc 更复杂一些
# 4.2 OOP(Object-Oriented programming,面向对象编程) vs. GP(Genic Programming,泛型编程)

- 许多大型 OOP 库会有很复杂的继承关系,很多虚函数,标准库中则很少有这种构造
- OOP = 数据 + 操作
- list 类中有自己的
sort()- 原因是能够符合
first+(last-first/2)中 + - / 运算的迭代器一定是 RandomAccessIterator(随机访问迭代器),而 list 在内存中是不连续的,它具备的迭代器只能向前或向后走,不能跳到特定的位置,所以 list 不能使用全局的 sort 排序
- 原因是能够符合

- GP 是将 data 和 method 分开来。
- vector 和 deque 类中都没有排序的操作,操作被单独的设计到一个全局的
sort()函数中,使用时通过迭代器传入头尾

- GP 有以下两个好处:
- Container 和 Alogorithm 团队可以各自闭门造车,然后用 iterator 沟通即可
- Alogorithm 通过 Iterator 确定操作范围,并通过 Iterator 取用 Continer 元素
- 如右上角的例子,函数只负责返回 a 和 b 里更小的那一个,至于 a 和 b 怎么比大小,应该是 a 和 b 的那种东西去定(它俩肯定是一种东西),这个思路也代表着操作符重载很重要

- 所谓算法,其内最终设计元素本身的操作,无非就是比大小。找一个东西是相等,不小于也不大于就是等于,排序也是类似的道理
max(string("zoo"), string("hello"))调用的是第一个版本的max(),字符串对于<的定义是,b 比 a 大,c 比 b 大,z 最大,不管长度,所以输出是 zoo 更大max(string("zoo"), string("hello", strLonger))使用了自己的比较方式,根据长度比大小,调用max()的第二个版本,得出 hello 更大
# 4.3 技术基础(操作符重载和模板)
# 4.3.1 操作符重载


- 第一页总结的很好
- 第二页的限制不需要记,写的时候翻资料即可

- 这个是链表迭代器的代码
# 4.3.2 模板
模板分为三大类:类模板,函数模板,成员模板

- 类模板

- 函数模板
- 这里的 class 可以写成 typename,class 是早期的写法

- 成员模板
- 后面我们的标准库源代码暂时看不到这个,所以不讲

- 特化的语法
template<> struct __type_traits<int>,由于泛化的 T 已经绑定为 int 了,所以后面要写上 int,前面的 template<> 中是空的
//泛化
template <typename T>
struct __type_traits{}
//特化
template <>
struct __type_traits<int>{}
1
2
3
4
5
6
7
2
3
4
5
6
7

__STL_TEMPLATE_NULL就是template<>,所以看到它出现就意味着要特化了

- 上面的特化也可以称为全特化

- 有两个模板参数,绑定其中一个
- 右边的例子是范围上的“偏”,范围限定为指针
# 5.分配器源码分析
幕后英雄,分配器好不好影响容器的性能好不好

operator new()底层都会调用到malloc()malloc()分配出的内存如右图所示。用户要求的大小是浅蓝色部分(size),malloc()实际分配了更多的东西,细节会在内存管理课讲- 附加的部分大小几乎是差不多的,所以你要求分配的空间越大,附加部分所占比例越小

- 这里列举了四个容器,其他也差不多,它们默认的分配器都是
allocator,所以下面我们将分析allocator的源码

- 分配器最重要的两个函数:
allocate()和deallocate(),而allocate()调用的是operator new(),operator new()调用的是malloc();deallocate()调用operator delete(),最终调用free() - 可见,VC6 的 allocator 只是用
operator new()和operator delete()完成allocate()和deallocate(),没有任何特殊设计 - 我们通常放的元素都不大,像 string 只有四字节,而这就意味着额外开销(malloc 多分配的内容)很大,甚至有可能比元素本身还大,如果元素有几百万个,会是很可怕的事情,但 vc 就是这么做的
- 右下角的代码证明我们也可以直接调用分配器,但不鼓励,因为没有人有心思记当时分配的内存有多大,大家只会记指针。但是容器去用没有问题,未来讲细节


- gcc 2.9 直接写出,虽然实现了分配器,但是容器并没有用这个实现的分配器,可以看出,容器用的是 alloc 分配器而不是 allocator
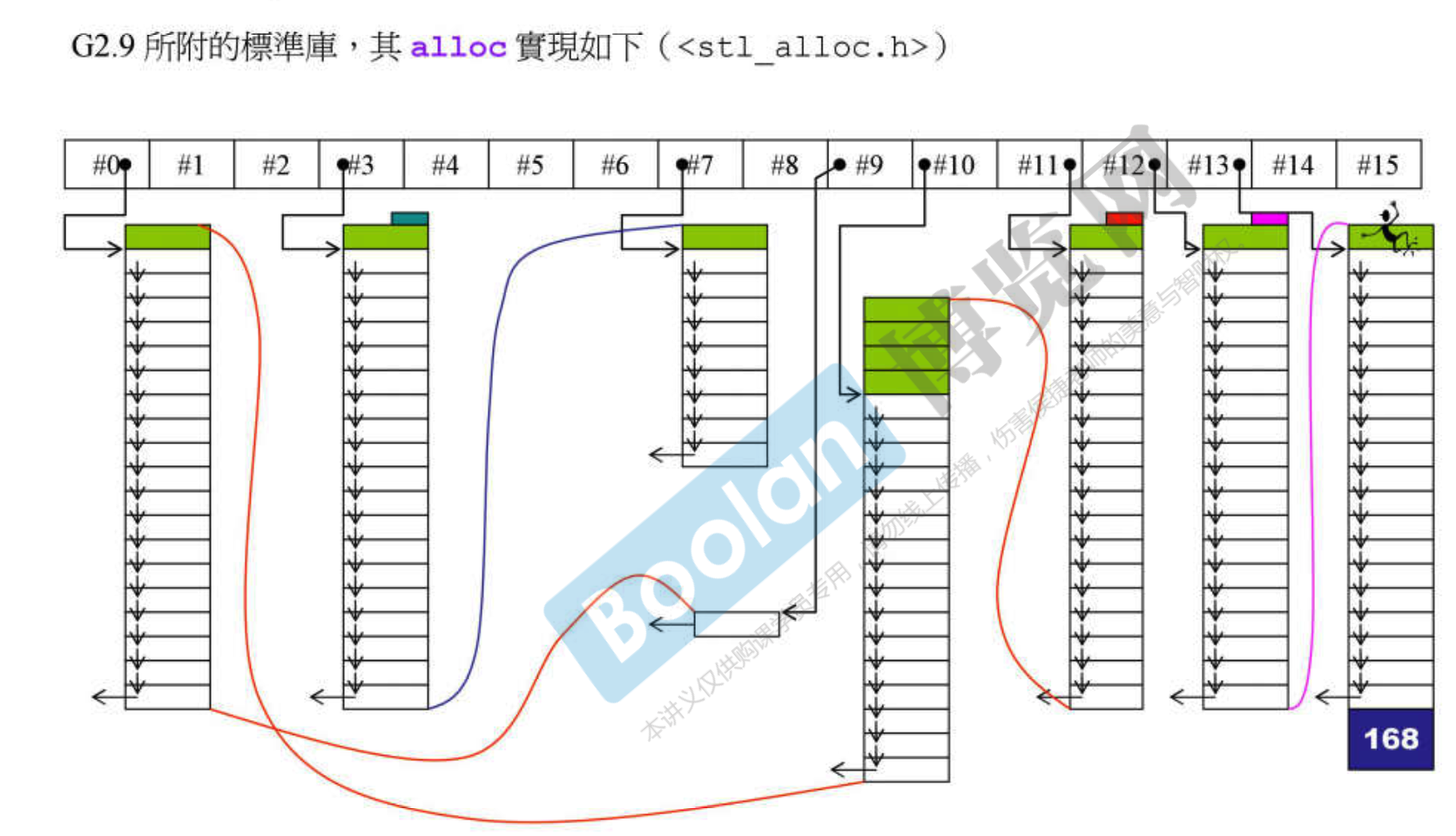
- gcc 的 alloc 分配器源码将在内存管理课上分析
- 思路是尽量减少
malloc()次数,设计了 16 条链表,每条链表负责特定大小的区块,如链表 0 负责八字节大小,链表 7 负责六十四字节大小。容器的大小会被调整到 8 的倍数大小,如 60 会调整到 64,分配器malloc()一大块内存,每块用单向链表做切割,切出来的每一块都不带 cookie(额外开销主要体现在 cookie 上,cookie 消耗 8 个字节) - 它也有缺点,内存管理时讲


- gcc 4.9 (不一定是 4.9 开始,可能之前就改了)中容器又改用了另一个分配器。变成和 vc 的情况差不多了,直接
malloc()
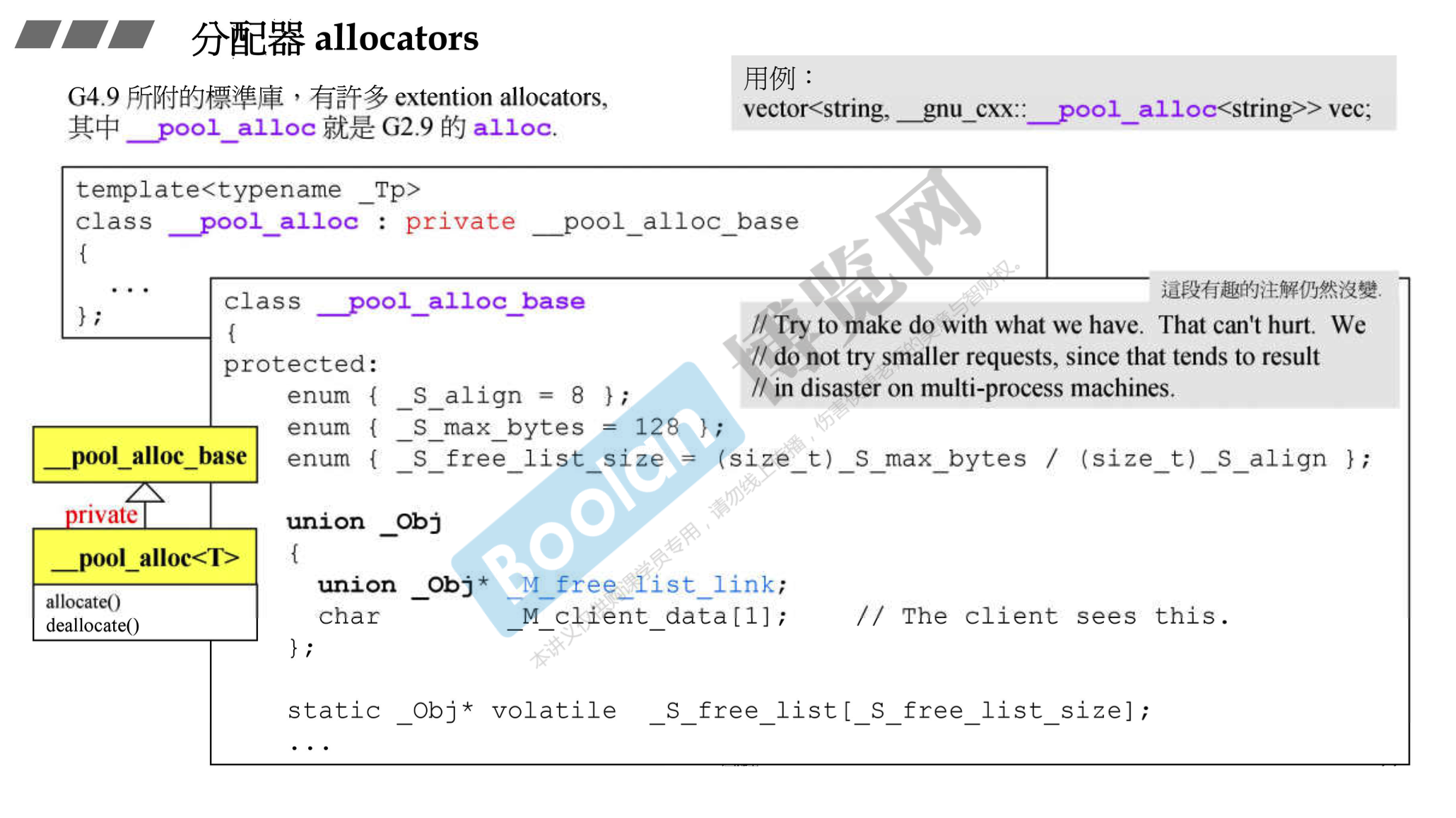
- 根据源代码,gcc 4.9 提供的众多 extension allocators 中的 __pool_allocate 就是之前 gcc 2.9 的 alloc
- 如果想使用它,把它指定为容器的第二个模板参数即可
vector<string, __gnu_cxx::__pool_alloc<string>> vec;
# 6.容器源码分析
# 6.1 list

- 不是最简单的,但是是最具代表性的
- 容器大小,指的是本身控制操作所需的大小(如需要几根指针),与控制的数据多少无关
- 整个 list 里的数据只有一个:node,是 list_node 指针,大小为 4 字节,所以 gcc 2.9 里 list 的大小就是 4
- list_node 有三个变量,向前指的指针、向后指的指针、数据,因此算占用内存的时候不能只计算数据大小,还要加上两个指针
- 为了满足前闭后开,最后一个元素并非指向第一个元素,而是指向一个空白节点,
begin()返回的是第一个节点,end()返回的是最后一个元素后面的空白节点

- 除了 array 和 vector,其他容器的 iterator 都要是 class 才能设计出聪明的动作,比方说 list 的 iterator++ 需要改成去找 next 指针,而不是真的直接找下一个内存地址
- 所有容器的 iterator 都会有一大堆的 typedef 和一大组操作符重载

++分为前置和后置的,++i是前置,i++是后置,为了区分,带参数的operator++(int)为后置,operator++()为前置;- 先看前置 ++ 的
operator++(),取出 node 指的 next 的值并赋给 node - 再看后置 ++ 的
operator++(int),先记住原来的值,然后进行++操作,最后返回原值。第一步里的self tmp = *this;并不会唤起 * 的重载,而是先来到被重载的 =,即拷贝构造,*this被解释为拷贝构造函数的参数。第二步的 ++ 唤起前 ++ 的operator++() - 在重载 ++ 时,设计者会向整数的 ++ 看齐,C++ 不允许后置 ++ 两次,即整数不可以
i++++,所以 iterator 的operator++(int)为了阻止两次 ++,返回的是数值 self,而非前 ++ 的引用 self&

- 除了 ++ --,另一个很重要的动作是获取数值
*,使用者想要取得 data,所以返回(*node).data->,思路类似,右侧有说明

- 刚才看 gcc 2.9 的一些细节有点奇怪,一个是
__list_node中向前向后的指针类型都是void*,还有就是__list_iterator要传三个参数,按道理来说只传一个 T(数据本身类型)就够了,第二个和三个在函数里生成即可 - 这里将 2.9 和 4.9 的代码上下并置
- 4.9 的
__list_iterator只需要传入一个参数,传入之后再取*和&定义出 pointer 和 reference - 4.9 节点的设计分为了两块,指针不再是
void*,而是指向自己的类型,这也是我们在学校学到的最好的做法

- 可以看出 4.9 的 list 变复杂了许多
- 4.9 的 list 里没有数据,他的大小就是父类的数据大小,父类数据有两个指针
_M_next和_M_prev,所以 4.9 的大小是 8 字节- 2.9 是一个 node 指针,大小为 4
# 6.2 迭代器的设计规则和 Iterator Traits 的作用与设计

- Traits 的中文是特征。Traits 是人为设计制造的一种萃取机,萃取出你丢给它的东西的特征。标准库中有很多种 Traits,除了 iterator Traits 还有 Type Traits、Character Traits 等等
- iterator 是容器和算法之间的桥梁,以
rotate()算法举例,看它想要知道 iterator 的哪些属性 return typename iterator traits<_Iter>::iterator_category();}想要萃取出 iterator 的 category。这个 category 指的是 Iterator 的移动性质,有的 Iterator 可以 ++,有的还能 --,有的可以跳着走(随机访问) +=3。所以rotate()想要知道它的 category,以便采取最佳的操作方式rotate()还想知道 iterator 的 difference_type 和 value_type。- value_type:iterator 指的东西是什么 type,如容器里存的是字符串,这个 type 就是 string
- difference_type:两个 iterator 之间的距离应该用什么 type 来表示,比方说容器中两个离得最远的指针相减范围也不超过 232-1,就可以用 unsigned int
- 类似这样的提问在 C++ 标准库中有 5 种,本例给出了三种,剩下两种为 reference 和 pointer(但这两种未曾在标准库中使用),我们称这 5 个 type 为 iterator 的 associated type,迭代器必须定义出来,以便回答算法提问

- 右侧是提问的写法(直接问)
- 大部分实现都用
ptrdiff_t定义 difference_type,它通常被定义为 long int - iterator_catefory 选择的是双向的标签,很合理

- 有时候传入算法的可能是一个指针,而非迭代器(泛化的指针),指针无法回答算法的问题,这时候就需要 traits 了(可以理解为加中间层)
- traits 可以区分是 class 设计出的 iterator 还是一般的指针
- 如果是 class 形式的 iterator,就直接用
::问 - 如果是指针,就用另外一种方式得到答案
- 如果是 class 形式的 iterator,就直接用

- 我们写一个 iterator_traits,如果传入的是 class iterator 就直接问,如果传入的是指针就进入偏特化的版本
- 注意两个偏特化的 valut_type 都是 T,为什么后面那个不加 const 呢?我们需要 value_type 的主要目的是用它声明变量,声明一个无法被赋值的变量没什么用,所以两个都是 T
- 下方框中的算法想要知道 iterator 的 value_type 时,通过把 iterator 放到 traits 中,间接问

- 指针的 category 是 random_access_iterator_tag
- 可以看出,算法发现手上是指针的时候,同样能回答五个问题

- 后面会讲其他 traits
# 6.3 vector

- 如果空间不足,不可能原地扩充,都是重新找一个两倍大的地方
- 用三个指针控制整个容器,start:起点,finish:终点,end_of_storage:整个空间的终点。所以 vector 的大小是 12 字节
- 前闭后开,finish 指向最后一个元素的后面一个
- 为什么
size()的实现是end()-begin()而不是finish-start呢?因为未来 vector 的实现方式会改变,不再只有 start、finish、end_of_storage,但 size 是 end()-begin() 这点不会改变

- 两倍增长一定发生在放元素进去的时候,所以这里找了最具代表性的
push_back() - 如果没有空间了,就调用
insert_aux(),insert_aux()上来依然要先检查有没有空间,因为它不光被push_back调用,还会被其他函数调用

- 两倍增长的代码
- 如果原大小为 0,则分配 1(个元素大小),如果原大小不为 0,则分配原大小的两倍。必须要有这样的特殊处理,因为 0 的两倍还是 0
- 调用分配器按照新的大小分配空间
- 分配空间后,先将原来的 vector 内容拷贝到新的 vector 中,然后再放新数据,并将插入点后的原内容也拷贝过来(因为可能会被
insert()调用) - 每次空间扩充都会有大量的元素拷贝动作,会调用拷贝构造函数,而原来的数据也要一个个删除,所以也会大量调用析构函数,要注意这些开销

- vector 是连续空间,迭代器无需单独设计成 class,指针即可
- 把迭代器丢入萃取机后,会进入偏特化的版本

- 4.9 的 vector 也变得复杂,但可以发现大小依然是 12

- 4.9 的迭代器,经过层层追踪,发现最后其实和 2.9 实现是差不多的

- 4.9 的迭代器本身是一个对象,不再是单纯的指针,对应类有 typedef 回答问题
# 6.4 array

- 比起 vector 更简单,把它包装成容器是为了让它也可以调用算法等
- TR1 (C++03)的意思是技术报告,介于 C++98 和 C++11 之间
- 和其他容器不同,必须指定大小
value_type _M_instance[_Nm ? _Nm :1!];非常直观,定义了数组,并且如果使用者指定的大小是 0,会自动变成 1- 没有构造函数和析构函数
- 直接用指针当迭代器

- 4.9 更复杂
- 可以
int a[100];,不可以int[100] b;,但是可以typedef int T[100]; T c;,G4.9 就是类似这种写法

- 前面已经介绍过双向链表了,这个只是变成线状单向了而已
# 6.5 deque

- 分段连续(连续是假象,分段是事实)
- 结构是分段并用 vector 串接起来,我们将它称为“控制中心”(网络也有人将其称为主控、中控等),vector 里存放的元素是指针,分别指向各个 buffer。往后扩充仅需分配一个新的 buffer 再串到后面即可,往前扩充同理
- 迭代器中的
node指向控制中心,first和last指的是某段 buffer 的头和尾,这样如果走到某个 buffer 的尾部了可以通过控制中心跳到下一个 buffer,cur是迭代器正在指向的元素。同一个 buffer 中first和last都不会变,++ 或 -- 是cur在变,如果去到上一个或下一个buffer,四个参数都会变动 - 几乎所有的容器都维护着两个迭代器,分别指向头和尾,deque 也不例外,所以图中下方画了两个迭代器

- map 是 T**(因为 map 指向的每个元素也都是指针),map_size 是控制中心的大小
- 每个 iterator 占 44=16 字节,map 和 map_size 各占 4 字节,所以一个 deque 的大小为 162+4+4 共 40 字节
BufSiz的默认值是 0,这里会涉及到__deque_buf_size()函数,如果这个值不是 0,比如 5,那么buffer size 就是 5;如果这个值是 0,会看元素大小,如果这个元素很大,大于 512 字节,那么每个缓冲区只放一个元素,即 buffer size 为 1,如果元素大小小于 512,那么 buffer size 就是 512/sz(如元素大小为4,那么就是 512/4)

- 迭代器的 category 是 random_access_iterator_tag,给外界制造连续假象

- 因为插入元素肯定是要往前推或往后推,deque 聪明的一点是会判断插入位置离哪边更近一些(比方说总共有 10000 个元素,要在第五个位置插入,当然是把前四个往前推更快)
- 一开始先判断是不是在头尾插入,是的话交给
push_front()或push_back()去做,都不满足再调用insert_aux()函数完成

insert_aux()先判断离头部更近还是离尾部更近,然后执行对应的操作往前推或往后推
# 6.5.1 deque 如何模拟连续空间
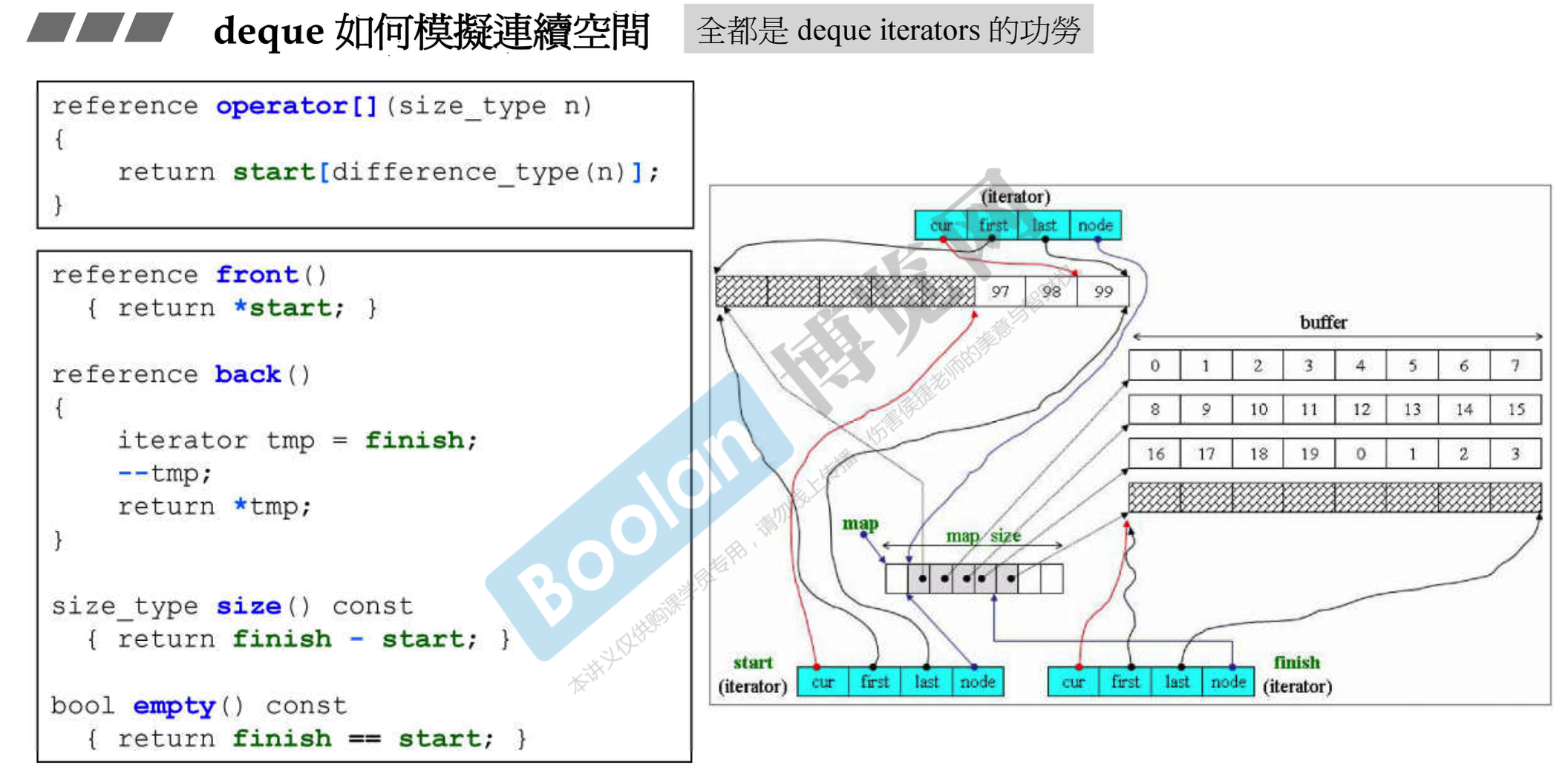
front()直接返回 start 指的内容,back()返回 finish 指的前一个元素(因为 finish 指的是最后一个元素的后一个),size()是 finish-start,但-肯定是做了重载的

*是取cur的值。->没什么好说的-计算两个迭代器间隔了多少元素,node - x.node - 1是两个迭代器在控制中心的距离,然后乘每个缓冲区里的元素个数,最后加上两个迭代器在各自缓冲区内相差的元素数- 为什么要 -1?假设一个位置是 1,一个位置是 5,这两个之间其实只有 3 个缓冲区(2、3、4)

- 同样分为前置 ++ 和后置 ++,先 +,再检查 + 完之后有没有到达边界,如果到达边界就跳到下一个缓冲区的起点
- -- 则是先判断在不在这个缓冲区起点,在的话就跳到前一个缓冲区的最末端

- 因为是模拟成了连续空间,所以应该可以随意移动位置,于是提供了 + 和 +=
- 先判断计算完后是否会落在同一个缓冲区,如果要落到别的缓冲区,就计算要跨越多少个缓冲区,然后再退回控制中心切到正确的缓冲区,最后计算到正确的位置

-=相当于+=负的- 因为是模拟成连续的,自然也要能用中括号

- 4.9,和其他几个容器形式差不多
- 大小依然是 40
BufSiz参数被去掉了,无法自己指定每个 buffer 的大小

- 补充前面没有提到的,控制中心在空间不足的时候会扩充两倍(毕竟是 vector),但拷贝的时候是拷贝到新空间的中段,这样能够保证前方和后方都有余裕
# 6.5.2 queue 和 stack

- queue 和 stack 无需重写功能,仅需内含一个 deque,再封锁住一些功能即可
- 它们俩都是转调用
c的函数,c就是 deque - 从技术上讲,不算容器,算容器适配器

- 从源代码的角度,如果另外一种容器也能提供这些函数让 queue 和 stack 转调用,那么就可以把 deque 换成别的。根据验证,list 也可以,既然 STL 选择了 deque,说明 deque 性能更好
- queue 和 stack 都不允许遍历,也不提供迭代器

- stack 可以选择 vector 作为底层,queue 不行,因为 vector 不能
pop_front()。由此可以看出编译器不会对模板做全面检查,这也意味着,如果你不调用 queue 的pop(),其他函数都可以调用通过 - queue 和 stack 都不能选择 set 或 map 作为底层
# 6.6 rb_tree
# 6.6.1 RB-tree 深度探索

- 不讲红黑树具体的概念,只讲 STL 如何实现以及一些关键点
- 红黑树是一种自平衡二叉查找树
- 遍历红黑树会得到排序状态(sorted)。红黑树从最左边开始,会先走左边,再走右边。对应图,
begin()是最左边的 5,end()是最右边的 15 - 不可以用迭代器赋值,会破坏红黑树的规则。在编程层面并不禁止这件事,因为用作 map 时,虽然 key 不可改变,但 data 是可以改的
- 红黑树设计本身并不强制 key 不可重复,它提供
insert_unique()和insert_equal(),前者在遇到重复的 key 时不会异常也不会报错,只是不会把它插入进去,后者则允许 key 重复

- 红黑树有 5 个模板参数,但是好在我们不会直接用它,而是用它更上层的 set、map
- 我们将 key 和 data 合称为 value
KeyOfValue告诉红黑树在 value 里 key 要怎么拿出来;compare告诉红黑树 key 怎么比大小- 红黑树有三个数据,
node_count是节点数量,header是指向红黑树节点的指针,key_compare是你传给它的那个比较函数(仿函数)。node_count 是 unsigned int,4 个字节,header 是指针,4 个字节,key_compare 是函数,没有数据,理论大小是 0,但实际上编译器会认为大小为 0 的 class 创建出的对象大小为 1,所以大小是 4+4+1=9。按照 4 的倍数对齐后是 12。 - header 就像双向循环链表里的虚空节点一样,是为了实现方便而放进去的

- 通过编写测试函数验证对红黑树的理解
- 这里的设计是 key 就是 value,value 就是 key,
identity<>是仿函数,传什么给它,它就传回来什么,less<>用<比大小

- 测试用例
- 通过 size 的可以看出
insert_unique()和insert_equal()的区别


- 红色是 4.9 改动的地方,类和函数的名称都变了
- 输出结果一致

- 4.9 有总共四个数据,
_M_color是枚举,_M_parent``_M_right``_M_left是三个指针加起来共 24 个字节
# 6.6.2 set 和 multiset

- set/multiset 的 value 和 key 是合二为一的,key 就是 value,value 就是 key
- set/multiset 提供遍历操作和迭代器,遍历后获得的是排序状态
- 我们无法用 set/multiset 的迭代器改变元素的值,因为不能改 key
- 区别
- set 元素的 key 必须独一无二,因此
insert()调用的是 rb_tree 的insert_unique() - multiset 的 key 可以重复,因此
insert()调用的是 rb_tree 的insert_equal()
- set 元素的 key 必须独一无二,因此

- 可以看到,set 里的迭代器是 const iterator,避免使用者改变元素,破坏红黑树
- set 所有操作都是转调用底层的 t,t 就是红黑树,可以认为它是容器适配器
# 6.6.3 map 和 multimap

- map/multimap 的排序依据是 key
- map/multimap 提供遍历操作和迭代器,遍历后获得的是排序状态
- 我们无法用 map/multimap 的迭代器改变元素的 key,但可以用它来改变元素的 data
- 区别
- map 元素的 key 必须独一无二,因此
insert()调用的是 rb_tree 的insert_unique() - multimap 的 key 可以重复,因此
insert()调用的是 rb_tree 的insert_equal()
- map 元素的 key 必须独一无二,因此

- key 和 data 被包成了一个 pair,注意它把 key 设为了 **const **以避免用户修改

- map 独有的
[],返回和中括号内值相对应的 key 的 data,如果这个 key 不存在,就创建这个 key - 这个
[]首先调用lower_bound()算法,这是二分查找- 如果有重复元素,
lower_bound()会返回其中的第一个;如果找不到,会返回最适合安插这个 key 的点
- 如果有重复元素,
# 6.7 hashtable
# 6.7.1 hashtable 深度探索

- 假设一个元素有 232 种变化,存储就要分配这种类型元素的大小*232 的空间,这显然不可能,而且这个元素只是可以有这么多种变化,会不会真的有那么多也不好说
- 如果空间足够大,编号为几的元素就放到几号位置,现在空间不是那么大,就要用编号%空间大小,这时可能会发生碰撞。

- 为了解决碰撞,采用链表把余数相同的串起来,即 Separate Chaining(分离链接法)
- hash table 里放的一般都是对象而不是数字,图上的数字是计算得到的 hash code
- 如果链表太长,也会影响到查找效率,目前采取的做法是,如果元素数量 >= 桶的数量,就将桶的数量增长两倍,然后重新打散
- 桶的数量一般会选择质数,所以不是严格的两倍,而是选择两倍附近的一个质数,如 53*2=106,最后会选择 97。gcc 2.9 的做法是直接将这些质数写死,参见右上角

- 六个模板参数,
Value和Key和之前一样;HashFcn传进来是一个函数(仿函数),负责把对象转成编号,算出来的这个编号称为 hash code;ExtractKey负责取出 key,因为散列里存放的可能是 pair,需要告诉它怎么从一包东西中取出 key;EqualKey告诉 hashtable 什么叫相等,这样它才知道要落到哪个位置上 - hashtable 有五个数据,前三个
hashequalsget_key分别就是模板参数中的HashFcn``EqualKeyExtractKey,buckets是图片右侧的一堆桶,是 vector,num_elements记录当前有多少个元素。前三个理论大小是 0,实际大小是 1;buckets 是 vector,大小为 12;size_type 是 unsigned int,4个字节,加起来就是 1*3+12+4=19,调整为 4 的倍数后是 20 字节 - 迭代器在走到一个链表的尾部时必须有能力到下一个桶,有点像 deque。图上绘制的箭头有误,
cur应该指向元素

- 编写测试函数
- 其中放入的元素都是 C 风格的字符串,value 就是 key,key 就是 value。比较字符串的
strcmp()函数返回的是 -1、0、1,但 hashtable 需要的比较函数必须返回 bool 值,所以自己编写了一个函数包装起来。 - hashtable 最重要的就是怎么把对象转成编号。用红黑树的时候只需要指定元素类型就可以了,但如果是 hashtable 做成的 set 和 map,必须写一个 hash 函数,这也算一种负担,好消息是标准库提供了一些,见下页

- 模板的偏特化,对
()操作符做重载,如果指明的类型在这里面,这些东西就会成为仿函数 - 这一页的都是数值,传 x 进去就传 x 出来
- 如果需要自己写,就要像这页一样,为
hash{}写一个特化版本

- 如果是 C 的字符串,就调用
__stl_hash_string()函数计算

- 左侧是 hashtable 里的部分函数,可以发现它调用了
bkt_num和bkt_num_key - 看一下箭头,发现这几个函数最后统统来到
bkt_num_key(const key_type& key, size_t n) const,它用的是 %。可见决定元素究竟落到哪个桶里用的就是取模
# 6.7.2 hash_ set, hash_ multiset, hash_ map, hash_ multimap
视频遗失
# 6.7.3 unordered 容器
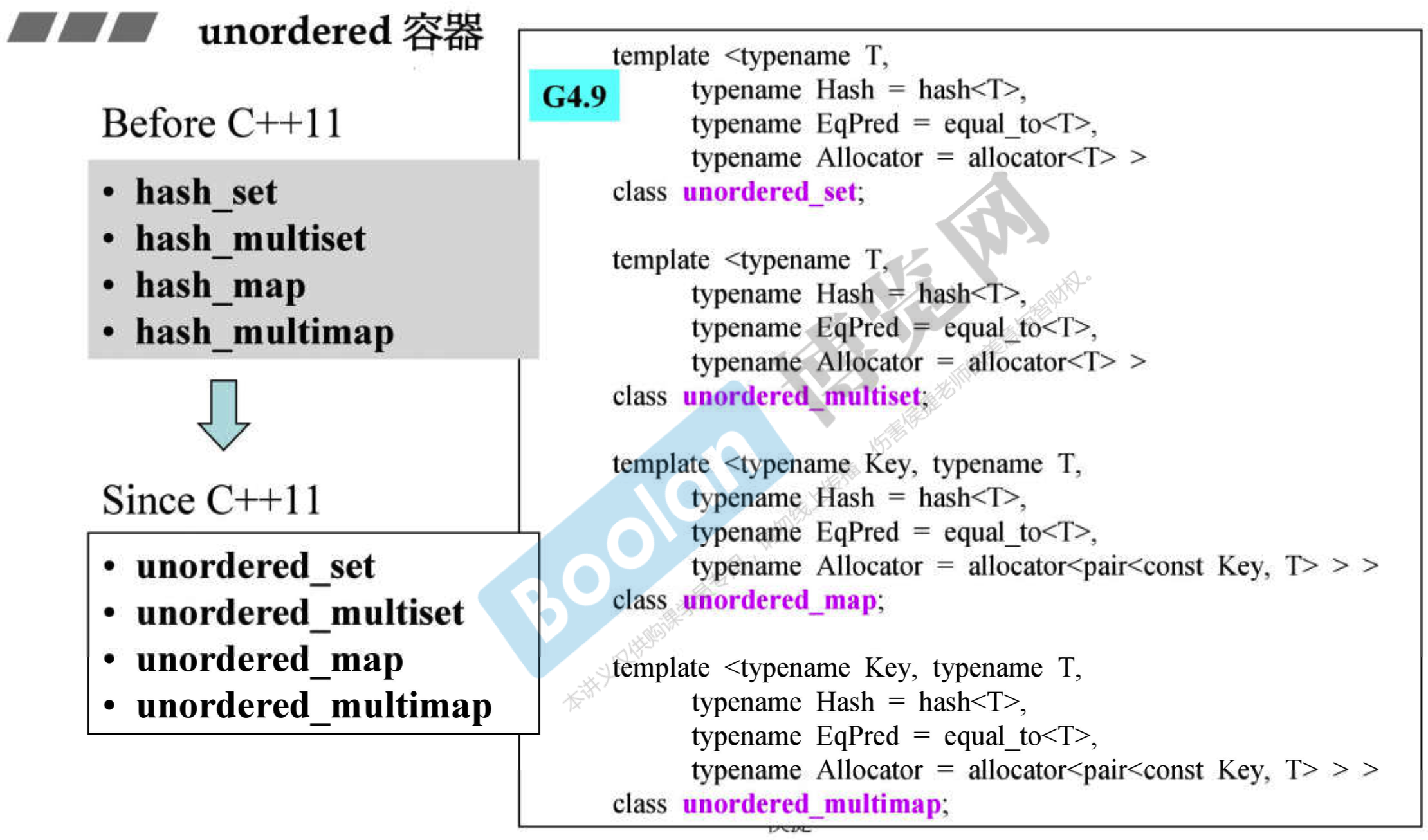
- 就是名字改了
# 7.算法
# 7.1 算法的形式

- 从语言层面上看,算法是函数模板,其他五个都是类模板
- 算法只能通过迭代器进行运算,虽然算法看不到容器,但是可以通过“问答”了解容器的情况,以便更好的进行操作。
# 7.2 迭代器的分类(category)

- Array、Vector、Deque 是随机访问迭代器,List 是双向迭代器,Forward-List 是单向迭代器,红黑树是双向迭代器,Unordered 容器视每个桶的链表是单向还是双向而定(代码验证是单向迭代器)
- 通过源代码可以发现,是 random_access_iterator_tag → bidirectional_iterator_tag → forward_iterator_tag → input_iterator_tag 的继承关系

- 测试代码,输出函数的模板实现和函数重载值得学习
- istream_iterator 和 ostream_iterator 比较特别,后面会专门讲
# 7.3 迭代器的分类对算法的影响

- 以
distance()举例,它主要是给其他算法使用的,负责计算两个指针的距离 - 如果是随机访问迭代器就直接减,如果是其他迭代器就从头走到尾并计数
- 许多算法中都是这样的结构,主函数根据迭代器分类调用次函数

advance(),主要也是给其他算法调用的,走 n 个距离- 如果可以跳,就直接
i+=n;如果是双向,就往前走或往后走;如果是单向,自然就只能往前走 - 小区别,
distance()是直接调用 traits 问,advance()把 traits 封装成了一个小函数再调用这个函数

copy(),只有三个参数,来源端的起点和终点,目的端的起点。看起来很简单,里面的实现却很复杂,为了找出一条效率最高的路线,无所不用其极has trivial op=()这里是检查拷贝赋值重不重要(trivial 的意思是不重要),如果 trivial 的话就跳过拷贝赋值

- 另一个例子
destory(),和copy()类似,要摧毁的对象的析构函数如果 trivial(不重要),就什么都不做

__unique_copy(),如果没有对 output iterator 做特殊处理,它也会跑到右下角处理 forward iterator 的函数,但是这个函数里面有 read 动作,而 output iterator 是 write-only,这是不允许的。于是标准库要针对 output iterator 单独写一个版本,避免 read 动作

- 算法是模板函数,不能在语法层面强制要求一定要传给它哪种迭代器,但如果迭代器类型不合适在执行时会报错,为此算法特意修改模板参数名来暗示需要的迭代器。比如
sort()函数是需要跳来跳去的,为了暗示,它没有用 T 或 I 命名迭代器的类型,而是用 RandomAccessIterator 命名。图中也列出了一些其他例子。
# 7.4 算法源码分析

- 可以看出 C 的算法是传各种参数,C++ 就像我们讲的一样是传迭代器了

accumulate(),累计,有两个版本- 第一个版本就是累加,第二个版本是做传进来的计算
- 右侧测试也测试了自己写的函数和仿函数

- 接受 first、last 和一个函数。调用函数处理从头到尾的每个元素

- 接受 first、last、旧值、新值,元素如果和旧值相同,就替换成新值
replace_if(),参数多了一个条件(Predicate,判断式,返回真假)replace_copy(),范围内所有旧值都以新值放到新的区间,其他则以原值放到新的区间

- 右侧整理了容器中是否带有同名的成员函数

- 发现有成员函数的还是这八个容器,因为这八个容器是关联容器,可以用 key 找到 value,所以可以想象它们会有更快地做法
- 全局这个
find()没有特殊的实现,就是一个一个找

sort()源码有好几百行,这里不给出,只示范用法- 注释中的并非屏幕实际输出内容,
()的部分是为了说明排序的范围 rbegin()和rend()中的“r”是“reverse”的意思,看输出结果,变成了反向的排序- 排序是需要跳的,list 和 forward_list 都不能跳,所以有自己的成员函数实现排序

rbegin()指的是最后一个元素,rend()指的是第一个元素前一个。因为取数的方式不同,需要套一个适配器

- 二分查找一定要先排序
binary_search()把工作都交给了lower_bound()lower_bound()还有个兄弟是upper_bound(),见图片下方,如果序列是 10 10 10 20 20 20 30 30(只是这么表示,实际上可能是红黑树),想要安插 20,lower_bound()会找最低点,把新的 20 放到 10 和 20 之间,upper_bound()则是找最高点,把新的 20 放到 20 和 30 之间。
# 7.仿函数

- 六大部件里最简单的
- 如果你希望设定一些额外的准则辅助实现算法,就可以用到函数或仿函数,如
sort()里的cmp() - 为了模仿函数,这个 class 必须重载
()

- 一些 gcc 独有,非标准的仿函数,好多都是我们之前用过的

- 可以看出用函数、用函数对象都可以,用
()产生的临时对象也可以 - 如果自己写仿函数,并希望以后能易于修改,被 adapter 改造,融入 STL,需要继承一些给定的基类。

- 一个参数的继承
unary_function,两个参数的继承binary_funcation,根据函数选择适当的来继承 - 只有继承之后,仿函数才是 adaptable(可适配的),以回答 adapter 的提问
# 8.适配器

- 改造既有的东西,如三个参数的改成两个参数的,修改函数名称等
- 不是单独的出现在某一块,而是出现在三个地方:容器适配器、仿函数适配器、迭代器适配器
- 比方说 A(适配器)改造了 B,那么 A 就代表了 B 给大家使用,而 A 做的主要的事都是交给 B 去做,从这个角度来说,适配器像是使用者和隐藏在某后的 B 的桥梁。既然 A 要用 B 的功能,有两种做法:继承和复合。接下来我们要讨论的适配器都是通过复合实现的,如容器适配器会内含一个容器
- 适配器改造什么,自己就要变现成什么,如它是容器适配器,表现出来就应该是容器的样子
- 之前迭代器用 5 个 typedef 回应算法的问题,仿函数也要用 2 个或 3 个 typedef 回应适配器的问题
# 8.1 容器适配器

- 最简单的适配器
- stack 和 queue 都内含 deque,选择性的封闭了一些接口,并且改了名字,如stack 把
push_back()改名为了pop()
# 8.2 仿函数适配器

less(x,y)本来是比较 x 和 y,但是现在我希望找出小于 40 的数,也就是我想让它和 40 比,就可以用bind2nd()函数将第二参数绑定为 40bind2nd()实际是用binder2nd执行操作,代码在图片右侧- 构造函数会将函数对象记录到 op,将数值记录到 value,等后面它被调用的时候,它才会调用 op 并将 value 作为第二参数
- 它是仿函数适配器,要表现成一个仿函数的样子,所以也要重载
() binder2nd是一个类模板,但很多人可能写不出less<int>()的类型,为了方便用户,STL 在外面包了一个bind2nd()给用户调用。因为在函数模板中编译器可以自动推导 op 的类型,所以它就可以把推导结果传给binder2nd作为模板参数- 灰色的代码就是问答环节。因为是
less<int>,后面绑定的第二实参应该是整数,为了做到检查,左侧bind2nd()中的Operation::second_argument_type就会问第二实参是什么类型,然后看 x 能不能转为这个类型,如果不能,这里就会编译失败,避免运行时才报错。右侧同理,binder2nd返回的应该是less<int>返回的类型,毕竟它只是适配器,不应该连返回类型都变了,所以它会问Operation::result_type,包括传进来的参数类型也不能乱,所以问Operation::first_argument_type。一个函数必须能回答这三个问题,才能和这个适配器搭配 binder2nd如果还要被其他适配器修饰,依然要回答问题,所以它继承了unary_function,很正规的写法- 设计模式:适配器模式

binder1stbinder2ndbind1stbind2nd现在都过时了,通通用bind取代。但因为之前也是标准里的,所以要用也依然可以用

not1()继续修饰右边的东西- 整个分析和上面完全一样,不过它只用记一个东西:pred

bind()可以绑定- 函数
- 函数对象(仿函数)
- 成员函数
- data member(类里的 data)
auto fn_half = bind(my_divide,_1,2);绑定第二个参数为 2,第 1 个参数则没有绑定,因此调用的时候必须给 1 个参数。其中_1是占位符(place holder),意味着实际调用的第 1 参数auto fn_invert = bind(my_divide,_2,_1);两个参数都空出来没有绑定,并且将顺序反了过来,用的时候第 1 实参会落到_1的位置,第 2 实参会落到_2的位置上auto fn_rounding = bind<int>(my_divide,_1,_2);指定了模板参数(也只能指定一个),这个参数代表了返回类型。前面几个都没指定,return type 就是它绑定的东西的 return type,即 doubleMyPair ten_two{10,2};是 C++11 的写法,代表着给初值- 成员函数其实有一个看不见的实参:this,所以要么写上占位符:
auto bound_memfn = bind(&MyPair::multiply, _1);要么写上绑定谁:auto bound_memdata = bind(&MyPair::a, ten_two); int n = count_if(v.cbegin(), v.cend(), not1(bind2nd(less<int>(),50)));其中的cbegin()和cend()意味着 const,传回来的迭代器是 const,不修改内容。返回的是不小于 50 的,即大于等于 50 的,有 5 个bind()分两行。auto fn_ = bind(less<int>(), _1, 50);cout << count_if(v.cbegin(), v.cend(), fn_)<< end1;,返回小于 50 的,有 3 个。
# 8.3 迭代器适配器

- 逆向迭代器的 5 个 associated types 都与正向迭代器相同
- 关键是取值的部分,逆向迭代器取值就是正向迭代器退一个取值。因为
rbegin()其实和end()差了一格 - 逆向的
++就是正向的--,反之亦然。逆向的+n就是正向的-n。

copy()只管赋值,不管目的端空间充不充足,所以如果目的端空间不够,就可能赋值到不该赋的地方。而如果加入inserter(),就可以自己弄出一块空间来- 因为链表不是连续空间,所以这里不能直接迭代器+3,而是调用了
advance()函数 - 这里非常巧妙地使用了操作符重载,解决 copy 已经写死了,只能赋值的问题
- 实际执行的是
insert_iterator, 巧妙在=是作用在 result 身上的,而 result 现在是inserter(foo,it),我们将赋值操作接管了,接管后改成调用这个容器的insert()
# 8.4 未知适配器

- istream_iterator 和 ostream_iterator 都不属于前面的三种适配器,所以算未知
std::ostream_iterator<int> out_it(std::cout, ",");第二参数的,是分割符号- 同样通过操作符重载。先将
cout存到s,将,存到delimiter,赋值的时候把value丢到cout,如果存在分隔符,把分割符也丢出去

- 使用 istream_iterator 定义出两个对象,eos 和 iit。eos 是 end of steam,作用类似标兵,没有参数,意味着 cin 的结束。iit 有参数,参数为 cin,根据源码,这个有参数的对象一旦创建,就会开始等待用户输入了
++iit的意思就是再读一个输入(见++的重载)

copy()把从cin()读到的数据不断放到容器里
# 9.STL 周边技术与应用
# 9.1 一个万用的哈希函数

- 基本的数据类型无非就是数字、字符串,既然它们都已经有了哈希函数,有没有可能把我们自己设计的数据结构拆分成这些,然后把它们各自的 hash code 加起来作为这种元素的哈希值?
- 两种形式都可以,左侧是类里的成员函数,右侧是普通的函数,重要的是函数内部怎么做。
size_t(*)(const Customer&)意思是函数的类型

- 假设 Customer 里有三个数据,fname、lname(意味 first name 和 last name)和 no
- 左上角的写法不是不行,但经验认为这样写太天真,可能会产生较多的碰撞
- TR1 开始提供了
hash_val(),比直接加要好- ① 接受的模板参数是任意个(因为用户调用的时候传入的参数是不确定的)
- ② 接受的模板参数也是任意个,但是函数的第一个参数是
size_t类型的 - ③ 函数的前两个参数和 ② 相同,但没有第三个参数
- ④ 是改变种子,本质就是越乱越好
hash_val(c.fname, c.lname, c.no);的第一个参数不是size_t类型,所以会调用到 ①。① 给参数加上一个 seed 参数后传给 ②。② 先对 seed 调用 ④,再继续调用 seed 和参数,每次 ② 都会把参数拆成 1 个和多个,如果参数依然还剩多个就递归调用自己,只剩一个参数的话就调用 ③,简单来说就是逐一取 val 改变 seed。

- 那个神奇的 0x9e3779b9 其实是黄金比例

- 4.9 下编写的测试代码,6 后面应该是 7、8、9、10,图上抄错了,不影响结果
- hh 代表哈希函数
%11是因为桶有 11 个,这样可以输出落到哪个桶里

- 除了开头说的两个形式,还有第三个形式,为自己的元素类型写一个偏特化版本

- 为 MyString 写特化版本,参考标准库中 string 的形式(2.9 里没有 string 的哈希函数实现,只有 char* 的,但 4.9 有)
# 9.2 tuple

- 能组合任意数量的任意类型
tuple<string,int,int,complex<double>> t;有趣的是,t 的大小并非是 4+4+4+16=28,而是 32,原因未知tuple<int,float,string> t1;的大小是 12,符合预期get<0>(t1)是把 t1 的元素的第一个元素取出来- 也可以用
make_tuple()配合 auto 来创建一个 tuple,无需指定类型,编译器会为我们自动推导 - tuple 可以比大小,可以整体赋值。
tie是把这三样东西和 tuple 捆绑在一起,类型要一一对应,捆绑之后 i1、f1、s1 就等同于 t3 中的 77、1.1、"more light"- typedef 后可以用
tuple_size获取元素个数,用tuple_element获取第 n 个元素,这些都不是调用参数,而是对类型做操作,算是 meta programming(元编程)

- 同样用到了参数可变模板配合递归,非常漂亮
- 但是哈希函数的递归是不断调用,这里的递归是不断继承,头部继承尾部。到最后没有参数可以继承的时候就会走到最上方的特化版本(空类),结束递归
head()和tail()的分析见图片中间
# 9.3 type traits
# 9.3.1 type traits 测试

- 2.9 的 type traits 比较平淡
- 六个 typedef
this_dummy_member_must_be_first和实现有关,不细讲has_trivial_default_constructor默认构造函数重不重要has_trivial_copy_constructor拷贝构造重不重要has_trivial_assignment_operator拷贝赋值重不重要has_trivial_destructor析构函数重不重要is_POD_type是否为 C 风格的 struct
- 后面五个默认回答都是 false,即重要。如果你自己写一个类型,你知道哪个不重要,就可以为这个泛化的设计写出特化的版本。如下面两个示例,int 和 double 这五个都不重要,它们本来也没有这些构造函数之类的
__type_traits<Foo>::has_trivial_destructor就是提问的方式- 实用性不是很高,许多人在写自己的类的时候都想不到还要特化一个 traits

- C++11 提供了几十个 type traits,可以发现有和之前对应的,但是改名了
- 不再需要用户自己实现偏特化,只要把类丢给它它就能回答问题

- 测试代码
- 丢了一个 string 进去
- 一个类如果有指针,大概率是要写析构函数的,string 里有指针,也有析构函数(图中 546 行)。根据 OO,如果一个类要成为父类,析构函数就应该是 virtual 的,设计上 string 没有打算成为父类,所以析构函数就不是 virtual 的。然后看输出结果
has_virtual_destructor是 0,可见 traits 真的知道它有没有虚析构函数

- 很单纯,只有 int,没有成员函数,其实等同于 C 的 struct。果然,输出的
is_pod是 1

- 特意放了一个虚析构函数。
has_virtual_destructor是 1 is_polymorphic(多态)是 1,polymorphic class 是一个有声明或继承了虚函数的 class,它确实有虚函数

- Zoo 有构造函数、移动构造(move_construtor)、拷贝赋值
Zoo(const Zoo&) = delete的意思是不要拷贝构造函数,如果不这么写编译器会默认生成,同理,移动赋值也没要is_default_constructible是 0,因为已经自己写了构造函数,编译器不会再给你默认构造函数;is_copy_constructible是 0,因为拷贝构造被 delete 了;is_move_constructible是 1,确实有移动构造,is_copy_assignable是 1,确实有拷贝赋值;is_move_assignable是 0,因为移动赋值被 delete 了。都可以对应上。

- 复数只有实部虚部,没有指针,所以析构函数不重要。
__has_trivial_destructor是 1 - 注意,复数中不是没有析构函数,编译器会给它默认的析构函数,但那个里面什么都没做,所以不重要
# 9.3.2 type traits 实现

- 从最简单的
is_void开始,这里都是通过模板对类型做操作 - 它先把对判断没帮助的 const 和 volatile 关键字去掉(借助
remove_cv)。可以发现每个实际执行的地方都是一个泛化和一个偏特化,如remove_const,泛化就是传给 T 就返回(严格来讲不叫返回,更像是回答、回应) T,有 const 则会传给偏特化,返回去掉 const 的。 - 去掉 const 和 volatile 之后它会把东西丢给
__is_void_helper,它的泛化版本都回答假,如果是 void 特化就回答真。

is_integral也是先拿掉 cv,再丢给 helper,泛化回答假,偏特化回答真

- 蓝色都是没有出现在 C++ 标准库源码中的,推测是编译器实现的
# 9.4 cout

- cout 之所以可以接受那么多类对象,是因为标准对操作符
<<做出了非常多的重载

- 如果是自己写的类型,想要 cout,就要自己对
<<做重载
# 9.5 move

- move 是 C++11 中加入的,主要在另一门课中讲解
- 放到容器里的元素加不加 move 功能会对速度有很大的影响
- 每个画面的上半部分是 moveable 元素的测试结果,下半部分是 non-moveable 元素的测试结果,数量都是三百万。可以发现 moveable 元素会快很多
- 为什么三百万元素需要七百多万的拷贝构造?因为 Vector 双倍扩容的时候也要拷贝构造




- list、deque、multiset、unordered_multiset 在构造时差别都不大,因为它们都是节点式的,不像 Vector 一样是连续的,一定要两倍扩容
- 当然,它的影响不只存在于构造的时候,后面的操作都会影响,所以 2.0 很强调 move


- 静态的要在类外给初值
- copy 是深拷贝,不只把指针拷贝过来,还把指针指向的对象也拷贝过来。
- 浅拷贝就是 move 的动作,差别在于
&&上,其实就是把指针指过来,再把原来的指针断掉 - moveable 版本的析构函数要把指针删掉,并且为了避免同一个指针被删掉两次,要提前做检查
- 但是浅拷贝更危险,move 不能乱用,自己写代码的时候一定要确认之前的东西不会再使用了才能 move

M c11(c1)是 copy,M c12(std::move(c1))是 movec1.insert(ite, V1type(buf))是右值,临时对象,编译器知道不会再用了,就会自动去找 move 版本。而下面的 c1 不是临时对象,编译器不敢自作主张调用 move 版本,所以需要用M c12(std::move(c1))告诉编译器用 move 版本

- vector 的深拷贝就是把来源端拷贝一份到目的端

- 浅拷贝是调用
vector(vector && __x),做的事就是把来源端和目的端的三根指针交换(swap)

- 可以看到 string 有 move 版本,可以安心使用
其他参考: